Chapter 5. Characters and words
Version 3.1 (6 October 2023) – cf. version 3.0 (12 December 2019)
by Odd Einar Haugen and Beeke Stegmann
5.1 Introduction
When transcribing a text, the transcriber will usually make a distinction between the individual characters, the white space between some of the characters, the words made up by sequences of characters, and the punctuation marks which are inserted between some of the words. The actual encoding can be as straightforward as in the example below, introduced in ch. 2.3. Here, characters, punctuation marks and spaces have been typed directly from the keyboard:
Reiðr var þá Vingþórr
er hann vaknaði
ok síns hamars
um saknaði,
skegg nam at hrista,
skör nam at dýja,
réð Jarðar burr
um at þreifask.In a more complex encoding, the transcriber might like to identify the basic units as such, so that a distinction easily can be drawn between single characters, words, punctuation marks and the white space surrounding them. This chapter will discuss these basic units and how they can be encoded specifically, if needed, using elements like <c> for individual characters and <w> for individual words.
5.2 Characters
The basic unit in any transcription of an alphabetic script is the individual letters. In a linguistic context a distinction is often drawn between the abstract entity of a grapheme and the representation of graphs in a written document. Variant forms are referred to as allographs, e.g. the Roman type of “s” and the Fraktur (black letter) type. The terminology is analogous to the distinction between phonemes, phones and allophones. For a general introduction to this terminology, see e.g. Sture Allén 1971, Manfred Kohrt 1985 or Christa Dürscheid 2016.
In this handbook we shall adopt the terminology of the Unicode Standard. The fundamental distinction drawn is between characters and glyphs. Characters are, as Unicode defines it, “the smallest components of written language that have semantic value”, while glyphs are “the shapes that characters can have when they are rendered or displayed” (cf. Unicode v. 12.0, ch. 2.2 Unicode Design Principles). What the transcriber sees in a manuscript is a series of individual glyphs, and the act of transcribing essentially involves linking these glyphs to the characters at the transcriber’s disposal.
The concept of a character is similar to, but not identical with the linguistic concept of a grapheme. These concepts are notoriously difficult, but for the purposes of this handbook we believe that the Unicode usage is robust and sufficiently well-defined.
The Unicode Standard puts great emphasis on the fact that individual characters may be represented by a number of glyphs, and is therefore reticent to accept as new characters what it percieves to be variant glyphs. It will be obvious to most people that the various shapes of letters in printed type faces, such as Courier, Times, Lucida etc., should not be seen as different characters, as shown in ill. 5.1.
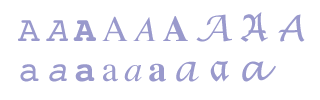
Ill. 5.1. Various shapes (glyphs) of the characters “A” and “a” in Courier, Times and Lucida typefaces.
Unicode draws a distinction between small (minuscule) characters such as “a” and large (majuscule) characters such as “A”, since there is a possible semantic value attached to each set of characters. Thus, “the white house” can refer to any house which is white in colour, while “the White House” refers (normally) to one specific building. It can be argued that the same applies to the distinction between regular characters, “a”, and italics, “a”. For example, while “Metope” refers a poem by the Norwegian author Olaf Bull, Metope (according to a widespread bibliographical practice) refers to the book in which this poem is published (a book which, co-incidentally, bears the same name as one of the poems contained in the book). However, Unicode does not regard italics (or bold type) as individual characters. There are good reasons for this, but the example serves to illustrate the fact that the definition of a character is not always clear-cut.
Medieval Nordic manuscripts and charters were written in the Latin alphabet from the very beginning. The basic inventory is thus the characters a–z / A–Z. They were supplemented by a number of new (or borrowed) characters, several ligatures and a variety of diacritical marks. There was also a large number of abbreviation marks in use, especially in Old Icelandic and Old Norwegian manuscripts. Some abbreviation marks behave as ordinary characters in the sense that they occupy a separate position on the base line, such as the Tironian note for ok ‘and’. We recommend that ordinary base-line characters and abbreviation base-line characters are encoded as individual, separate characters. In addition to the ordinary base-line characters, there were quite a few diacritical marks, which were placed above (or through or below) another character. There were also many abbreviation marks which appeared in similar positions. For this reason, we suggest that the rules for transcribing ordinary characters and abbreviation marks should be essentially the same.
We believe that it is possible to identify a base line in all texts, as shown in ill.
5.2. These characters
would be transcribed as abpþ or abpþ,
i.e. in the order of appearance on the base line. The last
character may be encoded with its Unicode codepoint, þ at
00FE, or with an entity,
þ. Both encodings are strictly equivalent.

Ill. 5.2. Position of characters on the base line.
If there are marks of any sort placed above, through or below any base-line character, we
recommend that these marks are transcribed
immediately after the base-line character. In general, we refer to
these marks as diacritics. As mentioned above, abbreviation marks are also frequently
placed in diacritical positions. Assuming that
the sign above h should be referred to with the entity
&er;, the
transcription of the very first word in ill. 5.3 would be h&er;.
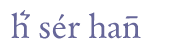
Ill. 5.3. Diacritical marks and abbreviation marks.
Diacritical marks are often seen as forming an integral part of a base-line character and
the whole is being encoded as a single character. This applies to accent marks, such as the one
above e in ill. 5.3. The combination of a base-line character and a combining mark
can be encoded as a single character, in Unicode referred to as LATIN SMALL LETTER E WITH
ACUTE and the hexidecimal code value 00E9. Alternatively, this letter can be decomposed and
encoded as a combination of LATIN SMALL LETTER E
and COMBINING ACUTE ACCENT. We would like to emphasise that both encodings are strictly
equivalent.
Abbreviation marks, on the other hand, are usually treated as separate characters and encoded as characters in their own right. From a purely graphical point of view, the distinction between the acute accent in “é” and abbreviation marks such as the “zigzag” mark and the bar, both exemplified in ill. 5.3, is far from obvious, but the semantics are different. The acute accent may in some manuscripts be used to signify length, but it is often used quite freely, sometimes only to distinguish one minim character from another. Abbreviation marks have a definite (if sometimes ambiguous) meaning and can be expanded into one or more characters; the zigzag mark above “h” in ill. 5.3 signifies “er”, and the bar above “n” signifies another “n”.
5.2.1 Rules for encoding characters
We recommend the following basic rules for encoding characters, irrespective of whether they are ordinary (alphabetic) characters or abbreviation marks.
1. Each character is encoded according to its position in the direction of writing.
2. Alphabetical characters on the base line are encoded first:
2.1 If the character belongs to the ordinary Latin character set a–z / A–Z (commonly
known as ISO 646 or Basic Latin) it is always encoded as such.
2.2 Characters
outside Basic Latin should either be encoded by Unicode codepoints or by entities, e.g.
either as abpþ (recommended) or as abpþ.
2.3 Characters
which are not part of the Unicode Standard must always be encoded by entities. See app. A for more details.
3. Abbreviation marks occupying a separate position on the base line are encoded in the
same manner as alphabetical characters. This applies to e.g. LATIN SMALL LETTER P WITH
STROKE THROUGH DESCENDER (for “per” or “par”), as explained in ch. 6 below.
4. Alphabetical characters with diacritical marks, e.g. “é”, are encoded in one of two equivalent ways:
4.1 As a base-line character + one or more combining marks. Thus the character é
would be encoded as e + &combacute; (the latter entity meaning
COMBINING ACUTE ACCENT).
4.2 As a composite base-line character and encoded with a
single Unicode codepoint or an entity. Thus, the character é would be encoded as
either é or as é.
5. Characters with abbreviation marks are encoded in the same manner as alphabetical characters, i.e. in one of two equivalent ways:
5.1 As a base-line character + one or more combining marks. Thus the first character in
ill. 5.3 above would be encoded as h + &er; (the latter entity meaning
COMBINING ABBREVIATION MARK “ER”).
5.2 As a composite base-line character and
encoded with a single entity. Thus the above character might be encoded with a single
entity, e.g. as &her;.
As a rule, we would recommend the first solution, since the number of combinations of base-line characters and combining abbreviation marks is very high. Furthermore, we recommend that the abbreviation mark is identified by the <am> element (if it is encoded as such, typically on the facsimile level) or by the <ex> element (if it has been expanded, in this case as “er”, typically on the diplomatic level). See ch. 4 above for an explanation of levels.
6. If there is more than one combining character, they are encoded in this order:
(a) Combinations with the base-line character within the x height of the base-line
character.
(b) Combinations with the base-line character outside its x height, but
still in contact with it.
(c) Combinations with the base-line character outside its
x height height and without any contact with it.
7. If there is more than one combining character in any of the three positions defined in (6) above, we refer to the rules in the Unicode Standard v. 12, ch. 2.11 Combining Characters.
5.2.2 Entities and Unicode values
By using entities it is possible to define as many characters as one believes are necessary for the transcription of a certain corpus of texts. However, since most applications now fully support Unicode, we recommend that characters in the Unicode Standard are encoded by their Unicode codepoints.
Note that the type of encoding is specifed at the very begining of an XML file. If the specification is
<?xml version="1.0" encoding="ISO-8859-1"?>entities must be used for all characters outside Basic Latin and Latin-1 Supplement.
Thus, “a”, “é” and “þ” can be entered directly, but characters like
&oogon; (LATIN SMALL LETTER O WITH OGONEK) must be encoded with an entity,
&oogon;.
If, however, the encoding is specified as
<?xml version="1.0" encoding="UTF-8"?>all characters in the Unicode Standard can be encoded with their Unicode codepoints, without resorting to entities.
In the TEI P5 Guidelines, all entities must be declared in a separate list. An extensive list of entities for Medieval Nordic texts can be downloaded from app. D.1.1 (2). An encoding using these entities will always be valid with respect to character encoding (but may, of course, be invalid for other reasons). The Menota entities are synchronised with the codepoints defined in the MUFI character recommendation, so that if a Menota text is displayed with a fully compliant MUFI font, all entities will be displayed correctly.
The Basic Multilingual Plane of the Unicode Standard has 65,536 different codepoints. This includes a large Private Use Area (PUA), comprising some 6,000 codepoints. This area can be used for characters not defined in the Standard (so far). Our present recommendation is to use this area for characters not included in the Unicode Standard and to coordinate the allocation of codepoints with the recommendations by the Medieval Unicode Font Initiative. It should be noted that the use of PUA is an interim solution. A long-term solution is to apply to Unicode for the inclusion of additional characters and/or use other rendering techniques (such as OpenType).
Code points in Unicode are usually given in hexadecimal format, in which each digit
spans a sequence of 16 positions, 0-1-2-3-4-5-6-7-8-9-A-B-C-D-E-F. Thus, 0001 equals 1
in the decimal system, 000F equals 15, 0010 equals 16etc. The whole range thus goes
from 0000 to FFFF (65,536). The PUA is located at E000–F8FF.
The Latin alphabet is the first to be described in the Unicode Standard. As was mentioned, many characters in Unicode can be defined in several ways, either as a single base-line character (including any diacritical marks) or as combination of a base-line character and one or more combining marks.
(a) Commonly used characters have a single description in Unicode. This applies to all base-line characters in the Latin alphabet.
| Glyph | Encoding | Code point | Unicode descriptive name |
|---|---|---|---|
| a | a |
0061 |
LATIN SMALL LETTER A |
(b) Composite characters may be described in more than one way. Thus, an “a with acute accent” can be encoded as a combination of an “a” and a combining acute accent or as a single character, “a with acute accent”. Both descriptions are equivalent:
| Glyph | Entity | Code point | Unicode descriptive name |
|---|---|---|---|
| á | a + &combacute; |
0061 + 0301 |
LATIN SMALL LETTER A + COMBINING ACUTE ACCENT |
| á | á |
00E1 |
LATIN SMALL LETTER A WITH ACUTE |
(c) Some characters are not found in Unicode and must therefore be assigned to the
Private Use Area (PUA), either as a character with its own codepoint or as a combination of
an existing character and a combining diacritical mark in the PUA. The ligature of “k”
and “ſ” is not included in the Unicode Standard (as of v. 12.0), and since there may be
good reasons not to encode it as a sequence of “k” + “zero width joiner” + “ſ”,
we have assigned it to a codepoint in the PUA, EBAE. This practice
is under consideration and may change at a future point. See the Medieval Unicode Font Initiative
for the current recommendation.
| Glyph | Entity | Code point | Descriptive name |
|---|---|---|---|
| | &kslonglig; |
EBAE |
LATIN SMALL LIGATURE K AND LONG S |
Encoding with entities referring to the PUA may look unnecessarily complicated. It should be borne in mind, however, that the great majority of characters are defined in Unicode, and in many transcriptions the need for special characters in the PUA will not arise. With appropriate fonts, the transcriber does not need to spend much time on technicalities of this type.
Finally, it should be noted that a text may be encoded with a mixture of Unicode code points and entities even for characters within the Unicode Standard. For the sake of clarity, some encoders might like to insert combining marks as entities. Thus, the example above might be encoded as:
h&er; sér han&bar;Or, with the element <am> for the abbreviation characters:
h<am>&er;</am> sér han<am>&bar;</am>The two abbreviation characters COMBINING ZIGZAG ABOVE and COMBINING OVERLINE are part
of the Unicode Standard, at 035B and 0305 respectively, so entitites are not really
needed. However, some XML editors may not show combining characters in correct
positions, and it is thus more legible to use entities, &er; for the
combining zigzag above, and &bar; for the combining bar above.
If an encoder, for some reason, would like to encode a character which is not in the Menota list of entities, this character has to be declared in the header of the file.
An ordinary Menota XML file will typically refer to the whole list of Menota entities in the third line of the file like this:
<!ENTITY % Menota_entities SYSTEM
'http://www.menota.org/menota-entities.txt'>
%Menota_entities;]>If, however, the transcriber would like to add a couple of entities not included in the Menota list, they must be specified as a sequence of the entity and its rendering:
<!ENTITY % Menota_entities SYSTEM
'http://www.menota.org/menota-entities.txt'>
%Menota_entities;
<!ENTITY trotdot "$">
<!ENTITY eacutesup "£">]>In this example, it is specified that the first entity, &trotdot;, is going to be displayed as the hexadecimal character 0024, the dollar sign, and the second, ésup;, as 00A3, the pound sign. These are oviously stop-gap measures, and the transcriber decides whatever rendering he or she thinks is appropriate. A long-term solution would be to work with Menota in order to add these entities to the Menota entity list.
5.2.3 Encoding characters as such
In some cases, a character should be encoded as such. That kind of separate mark-up allows for association with additional meta-data as well as easier processing. The TEI P5 Guidelines recommend the element <c> for this type of encoding, and we recommend using the attribute @type (and potential others) for further specification.
| Elements & attributes | Obl/Opt | Explanation |
|---|---|---|
| <c> | Contains an individual character. | |
| @type | Obligatory | Type of character. Suggested values: |
| ‘word’ | The character is a full word. | |
| ‘initial’ | The character is an initial. |
A character should, for instance, be encoded as such when it forms a word in itself instead of merely being part of a larger word. This can be the case if a character is the object of a grammatical discussion. A sentence like the following from the First Grammatical Treatise
X, hann er samsettr í látinu af c ok s.would thus be encoded as
<w><c type="word">X</c></w>, hann er samsettr í
látinu af <w><c type="word">c</c></w> ok <w><c type="word">s</c></w>.The usage of the attribute @type with the value ‘word’ distinguishes it from other kinds of characters one might want to mark-up. Note that the <c> element is placed within the element <w>. This might seem somewhat redundant in this case, since that information is also provided by the attribute. However, if a character behaves like a word, such as in a sentence like “The left descender of the x’es in this script go below the base line”, it has inflection and could easily be lemmatised as the noun “x”. (See ch. 11.2 on lemmatisation).
When displaying the text from the First Grammatical Treatise on the normalised level, one might choose to render the contents of the <c> element in italics, which would be possible with the suggested mark-up:
X, hann er samsettr í látinu af c ok s.
Individual characters are moreover marked-up as such, when the character in question is an initial or sentence initial. In that case, the character is part of a larger word, meaning that the entire word is enclosed by the <w> element, while only the visually highlighted initial is enclosed by the <c> element. A detailed description of how to mark-up initials in the transcription is provided in ch. 7.3. Note, however, that the visual rendering of initials in a manuscript usually is only encoded on the facsimile level, not on the diplomatic or normalised levels.
5.3 Words
5.3.1 Basic mark-up
The fundamental concept of the word is discussed in ch. 3.6 above, and in ch. 4.5 and ch. 4.6 an introduction is given to single-level and multi-level encoding of words. In this subchapter, we will introduce some further elements and attributes for the encoding of word or word parts, based on the TEI P5 Guidelines, ch. 17.1. Most examples are single-level transcriptions.
| Elements & attributes | Obl/Opt | Explanation |
|---|---|---|
| <w> | Contains an individual word. | |
| @lemma | Optional | States the lexical citation form of a word. |
| <m> | Contains a morpheme, i.e. a part of a word. | |
| @baseForm | Optional | States the base form of a morpheme. |
| <seg> | Groups one or more segments of text, e.g. words. | |
| @type | Optional | States the type of segmentation. Suggested values: |
| ‘nb’ | No break | |
| ‘enc’ | Enclitic |
As a rule, medieval Nordic manuscripts in the Latin alphabet were written with a clearly identifiable space between each word. This obviously facilitates the work for the transcriber, since the word is a basic linguistic unit in grammars and dictionaries. In a simple transcription, word division can simply be entered by the space bar on the keyboard.

Ill. 5.4. According to Barlaams saga ok Jósafats, falling into old sins is to behave like a dog returning to its own vomit. Note that the word “ſundr” in the 4th line of the illustration has been corrected to “hundr” by a younger hand. Holm perg 6 fol, f. 18vb, l. 18–24.
Thus, with a somewhat simplified character inventory the text in ill. 5.4 can be rendered as
En ef ver fallum i hinar fornno syndir. oc huerfum aptr. til hinnar fyrrv misverka sem hundr til spyu sinnar. þa kann lettlega at vera. at oss kunni til hannda at berazt. sem i guðspiall|eno segir.
Here, each word is delimited by a space (although, as discussed in ch. 5.5 below, a word sometimes extends over a linebreak). While the space bar in many cases would be a sufficient way of delimiting words, for several reasons we recommend that each word is identified with a separate <w> element (for “word”). The <w> element functions as a container for information on levels of text representation (ch. 4 above) and morphological analysis (ch. 11 below). In this example, each word has been identified by the <w> element, and the lemma (dictionary entry) specified as an attribute to the <w> element:
<w lemma="en">En</w>
<w lemma="ef">ef</w>
<w lemma="vér">ver</w>
<w lemma="falla">fallum</w>
<w lemma="í">i</w>
<w lemma="hinn">hinar</w>
<w lemma="forn">fornno</w>
<w lemma="synd">syndir</w>
etc. For practical reasons, each word has a separate line in this encoding. Unless otherwise specified, it is assumed that there is white space between each <w> element.
5.3.2 One word or two? Graphical and lexical words
Although words as a rule are separated by spaces in medieval Nordic manuscripts, there are many exceptions to this rule. For this reason, a distinction should be drawn between graphical words and lexical words. A graphical word is a sequence set out by space on either side, while a lexical word is a member of the set of word forms defined by grammars and dictionaries for the language in question. In the great majority of cases, graphical and lexical words are identical. However, we sometimes see that compounds are written as two separate words (“veiði kona” = “veiðikona”) or that a preposition and its object may be written as a single word (“aveiðiskap” = “á veiðiskap”).

Ill. 5.5. The ancient goddess Diana is introduced as a huntress, “veiði kona”, in Barlaams saga ok Jósafats. Holm perg 6 fol, f. 69va, l. 15–19. The word is located in the 3rd line of the illustration.
If the transcriber wishes to analyse two (or more) graphical words as a single lexical word, we suggest that this is done by putting the whole sequence within the <w> element:
<w>veiði kona</w> Information on e.g. lemma can be given as an attribute to the <w> element:
<w lemma="veiðikona">veiði kona</w> The sequence “veiði kona” thus appears within a single element. In other words, the transcriber interprets it as one lexical word, “veiðikona”. The space is left untouched, so that in a display of the transcription, the sequence will still show up as two graphical words, “veiði” and “kona”. However, since both graphical words are placed within a single element the lemma will refer to both parts.
In a multi-level encoding, the word will be transcribed with a space on the facsimile and diplomatic levels, but without a space on the normalised level:
<w lemma="veiðikona">
<choice>
<me:facs>veiði kona</me:facs>
<me:dipl>veiði kona</me:dipl>
<me:norm>veiðikona</me:norm>
</choice>
</w>
Stylesheets will simply display the whitespaces within the <w> element as they have been encoded, i.e. on the <me:facs> and <me:dipl> levels with a space, “veiði kona”, but without a space on the <me:norm> level, “veiðikona”.
The converse case is a single graphical word which the transcriber would like to analyse as two (or more) lexical words, e.g. “aveiðiskap” = “á veiðiskap”, as illustrated in ill. 5.6.

Ill. 5.6. In Barlaams saga ok Jósafats, the Greek god Adonis (in the text in accusative, Adonidem) is said to be keen at hunting, in normalised orthography “ágjarn á veiðiskap”. Holm perg 6 fol, f. 69vb, l. 12–14.
Each lexical word should be placed within a <w> element, and information on lemma, morphological form etc. can be given within each <w> element. However, to generate a correct display of the text, i.e. a display with no space between each part, we suggest that the <seg> element is used with a type attribute. The value ‘nb’ would indicate that there is no break between the parts in the <w> element. If the lemma is given by way of an attribute, the encoding would look like this:
<seg type="nb">
<w lemma="á">a</w>
<w lemma="veiðiskap">veiðiskap</w>
</seg> In some rather marginal cases, a sequence may be encoded as both types. A simplified example from Codex Regius is “aravk stola” which should be read as “a ravkstola”. This sequence might be encoded in this way:
<seg type="nb">
<w lemma="á">a</w>
<w lemma="rǫkstóll">ravk stola</w>
</seg> This encoding shows that “a” in “aravk stola” is a lexical word, i.e. the preposition “á”, and that “ravk stola” is another lexical word, i.e. the noun “rǫkstóll”. It will allow a correct display of the sequence, since it specifies that there should be no space between “a” and “rauk stola”, and the space between “rauk” and “stola” is also encoded (analoguous to the encoding of “veiði kona” above).
Enclitic words may be encoded in a smiliar way, e.g. “emk” which should be read as “em” + “[e]k” meaning ‘am I’:
<seg type="enc">
<w lemma="vera">em</w>
<w lemma="ek">k</w>
</seg> In some cases, it can be difficult to draw the line between the main word and the enclitic, for example when there is an assimilation between the two, “ert” + “þú” > “ertu” ‘you are’. We recommend to give priority to the main word and leave the enclitic in a reduced form:
<seg type="enc">
<w lemma="vera">ert</w>
<w lemma="þú">u</w>
</seg> Multi-level encodings follow the same rules, e.g. “scalltu” ‘you shall’:
<seg type="enc">
<w lemma="skulu">
<choice>
<me:facs>ſcallꞇ</me:facs>
<me:dipl>scallt</me:dipl>
<me:norm>skalt</me:norm>
</choice>
</w>
<w lemma="þú">
<choice>
<me:facs>u</me:facs>
<me:dipl>u</me:dipl>
<me:norm>þú</me:norm>
</choice>
</w>
</seg> Stylesheets will display the reading with no space on the <me:facs> and <me:dipl> levels, “ſcallꞇu” and “scalltu” respectively, but with a space on the <me:norm> level, “skalt þú”.
The morphological encoding of enclitic words is further discussed in ch. 11.3.2.11 below.
5.3.3 Encoding of word constituents
The encoder might want to encode constituent parts of a word, e.g. prefixes, roots, derivational forms, etc. We recommend using the <m> element (for “morpheme”) in such cases (cf. the TEI P5 Guidelines, ch. 17.1). This element may also be used for constituent parts such as “veiði” and “kona” in the examples above. The <m> element may contain information on level of text representation, lemma etc. We shall repeat the encoding of “veiði kona” above:
<w lemma="veiðikona">veiði kona</w>Now, if the encoder wishes to add lexicographical (or other) information to the two constituent parts, that can easily be done by inserting <m> elements in the <w> element:
<w lemma="veiðikona">veiði kona
<m baseForm="veiði">veiði</m>
<m baseForm="kona">kona</m>
</w>This encoding would make a clear distinction between lemmata on the first level of encoding, in this case “veiðikona”, and the base form, @baseForm, of each constituent part, in this case “veiði” and “kona”.
Lemmatisation is further discussed in ch. 11.2 below and is here only given as an example of a word-based type of mark-up. Grammatical information can also be conveniently attached to the word through the @me:msa (morphosyntactical analysis) attribute. This attribute is discussed in ch. 11.3 below.
5.4 Punctuation
Having introduced elements for the encoding of individual characters and words, it can also be useful to tag punctuation marks specifically. For punctuation characters in general, we recommend using the <pc> element. In some cases, it can be convenient to encode punctuation marks on more than one level of representation, such as the three levels <me:facs>, <me:dipl> and <me:norm> introduced in ch. 4 above.
| Elements | Explanation |
|---|---|
| <pc> | Contains a punctuation mark. |
| <me:facs> | Contains a reading on a facsimile level. |
| <me:dipl> | Contains a reading on a diplomatic level. |
| <me:norm> | Contains a reading on a normalised level. |
| <choice> | Groups alternative readings, such as <me:facs>, <me:dipl> and <me:norm>. |
Note the prefix “me:” which indicates that these elements belong to the Menota namespace and are not part of the elements defined in TEI P5 Guidelines. See ch. 2.8 above on the use of namespaces in TEI schemas. Since the levels of text representations offer parallel readings, we recommend that they are grouped by the <choice> element.
Note that punctuation characters such as the full stop may also be used as abbreviation marks. This is discussed in ch. 6.3.8, while a border case (between abbreviation and punctuation) is discussed towards the end of ch. 5.4.2 below.
5.4.1 Punctuation in a single-level transcription
In ch. 5.3.1 above, we said that a text can be encoded character by character. Punctuation marks are simply inserted where they occur in the manuscript, even if the position is wrong according to modern rules. If the actual punctuation in Barlaams saga ok Jósafats is added, the example above looks like this:
En ef ver fallum i hinar fornno syndir. oc huerfum aptr. til hinna fyrrv misverka sem hundr til spyu sinnar. þa kann lettlega at vera. at oss kunni til hannda at berazt. sem i guðspialleno segir.
If a text is encoded using the <w> element, we recommend using a <pc> element for punctuation marks. This is what an encoding looks like on a single, diplomatic level:
<w>En</w>
<w>ef</w>
<w>ver</w>
<w>fallum</w>
<w>i</w>
<w>hinar</w>
<w>fornno</w>
<w>syndir</w>
<pc>.</pc>
<w>oc</w>
<w>huerfum</w>
<w>aptr</w>
<pc>.</pc>
etc. The main reason for doing so follows from the encoding of more than one level of transcription. At a diplomatic level, the transcriber should encode the punctuation marks exactly where they are in the source, but at a normalised level, some punctuation marks should be suppressed, some should be retained and some should be added.
In addition to punctuation marks like FULL STOP, COMMA, COLON, SEMICOLON and HYPHEN,
there are a number of specific medieval punctuation marks, including an early form of
the QUESTION MARK and a PUNCTUS ELEVATUS. A full list of additional punctuation marks
can be found in the MUFI character recommendation
with appropriate character entities.
If the encoder wishes to represent specific types of punctuation marks apart from the ordinary ones, this can
be done by using the relevant entities, e.g. · for MIDDLE DOT,
&punctelev; for PUNCTUS ELEVATUS, etc. In all cases,
the punctuation mark should be
placed within the <pc> element.
5.4.2 Punctuation in a multi-level transcription
While punctuation on the <me:facs> and <me:dipl> levels in most cases will be identical, it is often radically different on the <me:norm> level. Here, many dots in the manuscript will simply be suppressed, while other punctuation marks will be added, including modern punctuation marks like quotation marks and exclamation marks. Suppressing a punctuation mark is simply done by leaving the element empty, while any supplied marks are encoded by adding a new <pc> element in which the <me:facs> and possibly also the <me:dipl> element will be empty. (See ch. 4.6 for more information on multi-level transcriptions.)
A text transcribed as
ok nu sagdi hann. þat er eigi sva. sem þu segir
on the <me:dipl> level would probably be rendered as
“Ok nú,” sagði hann, “Þat er eigi svá sem þú segir.”
on the <me:norm> level, allowing for some variation in the type of quotation marks and the order of comma or full stop and quotation mark. In a fully marked-up text, the dot after “sva” would probably be suppressed on the <me:norm> level, while a comma after “nu” would be added and the dot after “hann” would be changed into a comma. Finally, quotation marks would be added. However, other than punctuation characters (e.g. commas and full stops), quotation marks do not need to be written out by the transcriber, as recommended in ch. 5.6 below. Instead, the element <q> is simply placed around any part in direct speach, and it is left to the stylesheet to render the displayed text and potential punctuation characters inside quotation marks:
<q>
<w>
<choice>
<me:dipl>ok</me:dipl>
<me:norm>Ok</me:norm>
</choice>
</w>
<w>
<choice>
<me:dipl>nu</me:dipl>
<me:norm>nú</me:norm>
</choice>
</w>
<pc>
<choice>
<me:dipl></me:dipl>
<me:norm>,</me:norm>
</choice>
</pc>
</q>
<w>
<choice>
<me:dipl>sagdi</me:dipl>
<me:norm>sagði</me:norm>
</choice>
</w>
<w>
<choice>
<me:dipl>hann</me:dipl>
<me:norm>hann</me:norm>
</choice>
</w>
<pc>
<choice>
<me:dipl>.</me:dipl>
<me:norm>,</me:norm>
</choice>
</pc>
<q>
<w>
<choice>
<me:dipl>þat</me:dipl>
<me:norm>þat</me:norm>
</choice>
</w>
<w>
<choice>
<me:dipl>er</me:dipl>
<me:norm>er</me:norm>
</choice>
</w>
<w>
<choice>
<me:dipl>eigi</me:dipl>
<me:norm>eigi</me:norm>
</choice>
</w>
<w>
<choice>
<me:dipl>sva</me:dipl>
<me:norm>svá</me:norm>
</choice>
</w>
<pc>
<choice>
<me:dipl>.</me:dipl>
<me:norm></me:norm>
</choice>
</pc>
<w>
<choice>
<me:dipl>sem</me:dipl>
<me:norm>sem</me:norm>
</choice>
</w>
<w>
<choice>
<me:dipl>þu</me:dipl>
<me:norm>þú</me:norm>
</choice>
</w>
<w>
<choice>
<me:dipl>segir</me:dipl>
<me:norm>segir</me:norm>
</choice>
</w>
</q> In some cases, a dot should be interpreted as an abbreviation mark rather than a punctuation mark. We recommend that the dot is encoded by the ordinary full stop in Basic Latin, but that it is placed within the <am> element. A text transcribed as
nu fann kgr. engan mann þar
on the <me:facs> level would probably be rendered as
nu fann konongr engan mann þar
on the <me:dipl> level. In a fully marked-up text, the abbreviated word “kgr.” would be encoded within an <am> element around the dot (the abbreviation mark) on the <me:facs> level, while it would be expanded into “onon” (or “onun”) on the <me:dipl> level:
<w>
<choice>
<me:facs>nu</me:facs>
<me:dipl>nu</me:dipl>
</choice>
</w>
<w>
<choice>
<me:facs>fann</me:facs>
<me:dipl>fann</me:dipl>
</choice>
</w>
<w>
<choice>
<me:facs>kgr<am>.</am></me:facs>
<me:dipl>k<ex>onon</ex>gr</me:dipl>
</choice>
</w>
<w>
<choice>
<me:facs>engan</me:facs>
<me:dipl>engan</me:dipl>
</choice>
</w>
<w>
<choice>
<me:facs>mann</me:facs>
<me:dipl>mann</me:dipl>
</choice>
</w>
<w>
<choice>
<me:facs>þar</me:facs>
<me:dipl>þar</me:dipl>
</choice>
</w>
<pc>
<choice>
<me:facs></me:facs>
<me:dipl>.</me:dipl>
</choice>
</pc> In certain cases, a word abbreviated with a dot may occur at the end of a sentence, e.g.
nu fann hann eigi kgr.
This dot would be interpreted as an abbreviation mark and possibly also as a punctuation mark. On the <me:facs> level it would be encoded as no more than a dot (inside an <am> element), while on the <me:dipl> level it would be suppressed when “kgr.” had been expanded to “konongr”. The encoder might, however, add a dot as a punctuation mark within a <pc> element. That would certainly be the case on the <me:norm> level, possibly also on the <me:dipl> level, but not on the <me:facs> level:
<w>
<choice>
<me:facs>nu</me:facs>
<me:dipl>nu</me:dipl>
<me:norm>Nú</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>fann</me:facs>
<me:dipl>fann</me:dipl>
<me:norm>fann</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>hann</me:facs>
<me:dipl>hann</me:dipl>
<me:norm>hann</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>eigi</me:facs>
<me:dipl>eigi</me:dipl>
<me:norm>eigi</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>kgr<am>.</am></me:facs>
<me:dipl>k<ex>onon</ex>gr</me:dipl>
<me:norm>konungr</me:norm>
</choice>
</w>
<pc>
<choice>
<me:facs></me:facs>
<me:dipl>.</me:dipl>
<me:norm>.</me:norm>
</choice>
</pc> With this markup, a dot will be displayed after the word “konungr” on all three levels, but the dot on the <me:facs> level is classified as an abbreviation mark (since it occurs within the <am> element), while the dot on the <me:dipl> and the <me:norm> levels is classified as a punctuation mark (since it occurs within the <pc> element).
5.4.3 Punctuation marks as delimiters
In some manuscripts, certain words – typically short ones – are delimited by dots, often on both sides, sometimes only on a single side. One example can be found in Holm perg 34 4to, cf. ill. 5.7. Towards the end of the middle line in this illustration, the word “var” (written “ꝩͬ”) has been delimited by dots on either side.

Ill. 5.7. Encoding of a word delimited by dots. Landslǫg Magnúss Hákonarsónar. Holm perg 34 4to, f. 8r, l. 14–16.
We recommend that these dots are encoded as punctuation marks within the <w> element, so as to distinguish them from ordinary pause or sentence punctuation. In a multi-level encoding, they would be rendered on the facsimile and diplomatic levels, but not on the normalised level. The last part of the middle sentence in ill. 5.7 would then be encoded as:
<w>
<choice>
<me:facs>h&vins;ærgi</me:facs>
<me:dipl>hværgi</me:dipl>
<me:norm>hvergi</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs><pc>·</pc>v<am>&rsup;</am><pc>·</pc></me:facs>
<me:dipl><pc>.</pc>v<ex>ar</ex><pc>.</pc></me:dipl>
<me:norm>var</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>aðr</me:facs>
<me:dipl>aðr</me:dipl>
<me:norm>áðr</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>lıoſaræ</me:facs>
<me:dipl>iosaræ</me:dipl>
<me:norm>ljósara</me:norm>
</choice>
</w>
<w>
<choice>
<me:facs>en</me:facs>
<me:dipl>en</me:dipl>
<me:norm>en</me:norm>
</choice>
</w>
. . .Punctuation marks are also used as delimiters for numerals, especially Roman numerals. As stated in ch. 5.7 below, we recommend the same type of encoding.
5.5 Hyphenation
Like modern texts, medieval manuscripts were by and large justified, i.e. each line had approximatley equal length. As a consequence, words often were split with one part at the end of a line and the remaining part on the next line. However, hyphens were used a lot less than in modern texts, where they are more or less obligatory.
We recommend that hyphens are encoded whenever they occur in the manuscript, using the <pc> element. When this element encodes hyphenation, it may optionally have a @resp attribute specifying the person responsible for the hyphenation, e.g. a later hand. If the scribe is responsible for the hyphenation, we suggest that the @resp attribute be left out.
When there is no hyphen, we do not think it is necessary to add a hyphen in the encoding, as long as the word is placed within the <w> element, which also contains a <lb/> element. A hyphen can then be supplied by the stylesheet at one or more levels, based on the position of the <lb/> element within a <w> element. We suggest that a missing hyphen should not be displayed on the facsimile level, but on the diplomatic and normalised levels.
| Elements & attributes | Obl/Opt | Explanation |
|---|---|---|
| <pc> | Contains a punctutation character, such as a hyphen. | |
| @resp | Optional | States who is responsible for the hyphenation. Suggested values: |
| ‘scribe’ | The scribe of the manuscript. | |
| ‘mainscribe’ | The main scribe of the manuscript (if more than one). | |
| ‘laterscribe’ | A later scribe. |
If there is a hyphen in the margin of the line, we suggest this encoding:
This is how <w>hyphen<pc>-</pc><lb ed="ms" n="2"/>ation</w>
can be encoded when there actually is a hyphen in the manuscript. If the hyphen is missing in the manuscript, and that happens quite frequently, we suggest that no hyphen is encoded:
This how <w>hyphen<lb ed="ms" n="2"/>ation</w> can be encoded
when there is no hyphen in the manuscript. If a stylesheet displays the text line by line, such as the one used in the Menota archive, it is informative to make a distinction between hyphenation in the manuscript and hyphenation supplied by the editor. The former can be displayed by an ordinary hyphen and the latter by a middot, for example. Other stylesheets may display the text without showing the line beginnings in the manuscript, and thus do not need to make any distinction between the two types of hyphenation, such as the Menota stylesheets offered in app. F.3. The one exception is the <me:facs> level, where hyphens that are in the manuscript should always be displayed. For examples, see ch. 5.5.3 below.
At the normalised level, there will sometimes be hard hyphens such as in the name “Egill Skalla-Grímssonar” (also spelt “Egill Skallagrímssonar”). This type of hyphen should be encoded with the ordinary hyphen character:
This is how the name <w>Egill</w>
<w>Skalla-Grímssonar</w> can be encoded. The ordinary hyphen will be displayed in any position of the word, whether in the line or at the end of a line.
5.5.1 Hyphenation in a single-level transcription
The encoding of hyphenation in single-level transcription (cf. ch. 4.5) is essentially the same as in a multi-level transcription (cf. ch. 4.6). We give examples of both.

Ill. 5.8. Hyphenation in a manuscript. The Old Norwegian Homily Book. AM 619 4to, f. 47r, l. 1–4.
This is how the hyphenated word “hæ-góma” (normalised “hégóma”) in lines 3–4 in ill. 5.8 should be encoded on the diplomatic level:
<w>
hæ<pc>-</pc><lb ed="ms" n="4"/>góma
</w>
Ill. 5.9. Missing hyphenation in a manuscript. Henrik Harpestreng. NKS 66 8vo, f. 116r, l. 1–3.
The non-hyphenated word “hwilk-kæ” in ill. 5.9, lines 2–3 should receive this encoding, not recording any hyphenation:
<w>
hwilk<lb ed="ms" n="3"/>kæ
</w>5.5.2 Hyphenation in a multi-level transcription
In a multi-level transcription, the rules for hyphenation will be identical to the ones above. This would be the encoding of the hyphen in ill. 5.7 above:
<w>
<choice>
<me:facs>hæ<pc>-</pc><lb ed="ms" n="4"/>góma</me:facs>
<me:dipl>hæ<pc>-</pc><lb ed="ms" n="4"/>góma</me:dipl>
<me:norm>he<pc>-</pc><lb ed="ms" n="4"/>góma</me:norm>
</choice>
</w>When the hyphen is missing, as in ill. 5.8 above, we recommend that the encoder simply encodes the word as it is, leaving it to the style sheet to display a hyphen:
<w>
<choice>
<me:facs>hwilk<lb ed="ms" n="3"/>kæ</me:facs>
<me:dipl>hwilk<lb ed="ms" n="3"/>kæ</me:dipl>
<me:norm>hwil<lb ed="ms" n="3"/>kæ</me:norm>
</choice>
</w>In this example, the encoder might decide to render the word as “hwilkæ” on the normalised level, assuming that the line beginning in the manuscript had led to the dittography “hwilkkæ”.
Note that a line beginning will appear several times in a multi-level transcriptions, if it occurs within a word. Great caution must therefore be taken with automatic numbering of <lb/> elements.
In some cases, there may be a dash at the end of a line, which is not being used for hyphenation purposes. This dash can
be placed in an ordinary <pc> element, and the encoder may decide whether it should be represented by e.g. an
ordinary hyphen or, perhaps, as a dash, – for a somewhat longer dash than the hyphen,
or — for an even longer dash.
5.5.3 Display of hyphenation
The display of hyphenation varies with the stylesheets being used. Since texts must be aligned in the Menota archive, the display differs from that of the stylesheets offered in app. F.3 of this handbook.
In the Menota archive, hyphens in a manuscript will be displayed with a hyphen on all levels, while missing hyphens will not be displayed with any character on the <me:facs> level, but (as a help for the users) with a middot (00B7) on the <me:dipl> and <me:norm> levels. This is an approximate display:
| Facs | Dipl | Norm |
|---|---|---|
| 10 oc æro þæír þa ȷmıſkun konongs 11 oc ſuare þæír ꝼírí þat er aꞇ lo- 12 gum æıgu aꞇ ſuara 13 NU eꝼ hærs er 14 uon ȷlanð varꞇ. þa ſkulu 15 mænn víꞇa voꝛð ræíða. þa 16 ſkall lænðꝛ maðꝛ. æða vmboðs 17 maðꝛ gs laꞇa ſkera boð. en ſa |
10 oc æro þæir þa imiskun konongs 11 oc suare þæir firi þat er at lo- 12 gum æigu at suara 13 NU ef hærs er 14 uon jlanð vart. þa skulu 15 mænn vita vorð ræiða. þa 16 skall lænðr maðr. æða vmboðs· 17 maðr konongs lata skera boð. en sa |
10 oc eru þeir þá í miskunn konungs. 11 Ok svari þeir fyrir þat er at lǫ- 12 gum eigu at svara. 13 Nú ef hers er 14 ván í land várt, þá skulu 15 menn vitavǫrð reiða. Þá 16 skal lendr maðr eða umboðs· 17 maðr konungs láta skera boð. En sá |
At the end of line 11 in the table above, there is a hyphen in the manuscript, and this is displayed as such on all three levels. In line 16, there is no hyphen, and consequently no display on the <me:facs>. However, since “umboðs maðr” has been analysed as one word, a middot is displayed on the <me:dipl> and <me:norm> levels.
In the three Menota stylesheets offered in app. F.3 of this handbook, hyphens in a manuscript are displayed only on the <me:facs> level, since at this level, line beginnings are displayed according to the manuscript. On the <me:dipl> and <me:norm> levels, hyphens in the manuscript are not displayed, since the text is rendered in continuous lines on these levels. As for missing hyphenation, no hyphen is displayed on the <me:facs>, nor is any hyphen displayed on the <me:dipl> and <me:norm> levels. However, since the text is rendered in continuous lines on the latter two levels, words will be displayed without any breaks. See the examples below.
| Facs : approximate display using the Menota stylesheet in App. F |
|---|
| 10 oc æro þæír þa ȷmıſkun konongs 11 oc ſuare þæír ꝼírí þat er aꞇ lo- 12 gum æıgu aꞇ ſuara 13 NU eꝼ hærs er 14 uon ȷlanð varꞇ. þa ſkulu 15 mænn víꞇa voꝛð ræíða. þa 16 ſkall lænðꝛ maðꝛ. æða vmboðs 17 maðꝛ gs laꞇa ſkera boð. en ſa |
| Dipl : approximate display using the Menota stylesheet in App. F |
|---|
| oc æro þæir þa imiskun konongs oc suare þæir firi þat er at logum aigu at suara NU ef hærs er uon jlanð vart. þa skulu mænn vita vorð ræiða. þa skall lænðr maðr. æða vmboðsmaðr konongs lata skera boð. en sa |
| Norm : approximate display using the Menota stylesheet in App. F |
|---|
| oc eru þeir þá í miskunn konungs. Ok svari þeir fyrir þat er at lǫgum eigu at svara. Nú ef hers er ván í land várt, þá skulu menn vitavǫrð reiða. Þá skal lendr maðr eða umboðsmaðr konungs láta skera boð. En sá |
When using the Menota stylesheets in app. F.3, the hyphen in “lo-gum” (end of line 11) is displayed only on the <me:facs> level, otherwise not. Neither is the missing hyphen in “vmboðs maðr” (end of line 16) indicated on any level, but since “umboðs maðr” has been encoded in a single <w> element, it is displayed as a single word on the <me:dipl> and <me:norm> levels.
5.6 Direct speech and quotations
We recommend that direct speech is encoded with the <q> element for each turn in the dialogue (e.g. for each question and answer). In multi-level transcriptions, quotation marks will typically be displayed on the <me:norm> level, sometimes also on the <me:dipl> level, but never on the <me:facs> level. There were no quotation marks in medieval manuscripts, so a display on the <me:facs> level would be anachronistic.
Texts may also contain quotations from other sources. These are usually not indicated by quotation marks, but might be displayed by italics or the like, or perhaps by a note. Stylesheets will vary with respect to the display of quotations.
| Elements & attributes | Obl/Opt | Explanation |
|---|---|---|
| <q> | Direct speech. Contains a part of a dialogue. | |
| @type | Optional | May be used to indicate whether the offset passage is spoken or thought, or to characterise it more finely. Sample values: |
| ‘spoken’ | The part of the dialogue is spoken. | |
| ‘thought’ | The part of the dialogue is thought. | |
| <quote> | Contains a quotation from another source. |
Since the graphical form of quotation marks varies widely, we recommend encoding dialogue with the <q> element and leave it to the style sheet to decide which type of quotation mark to be displayed.
The <q> element is placed outside the word(s) in the dialogue, irrespective of whether the encoding is on one or more levels. This is a simplifed single-level example from Niðrstigningar saga in the fragment AM 233 a fol:
<w>Þeir</w>
<w>spurðu</w>
<w>þá</w>
<w>hverir</w>
<w>vǽri</w>
<pc>,</pc>
<q>
<w>er</w>
<w>þit</w>
<w>hafið</w>
<w>eigi</w>
<w>dauðir</w>
<w>verit</w>
<w>með</w>
<w>oss</w>
<w>í</w>
<w>helvíti</w>
<pc>.</pc>
</q>
<w>Þá</w>
<w>svaraði</w>
<w>annarr</w>
<w>þeira</w>
<w>ok</w>
<w>mǽlti</w>
<pc>:</pc>
<q>
<w>Enoch</w>
<w>heiti</w>
<w>ek</w>
<pc>.</pc>
</q>
etc. Note that on the normalised level, a comma or a colon will often be added in a <pc> element before a new turn in the dialogue, irrespective of whether there is a punctuation mark in the manuscript or not. Also note the position of the <q> element after the final <pc> element.
A succesful stylesheet will display this encoding so that the quotation marks are of the intended opening and closing type, that there is a space between an introductory comma or colon and the opening quotation mark, and another space after the closing quotation mark. This would be a correct display, in which Anglo-American quotation marks have been used:
Þeir spurðu þá hverir vǽri, “er þit hafið eigi dauðir verit með oss í helvíti.” Þá svaraði annarr þeira: “Enoch heiti ek, ok var ek við Guðs orði hingat fǿrðr.”
Depending on the specifications in the style sheet, French-style quotation marks (also frequently used in Scandinavia) may be selected for the display:
Þeir spurðu þá hverir vǽri, «er þit hafið eigi dauðir verit með oss í helvíti.» Þá svaraði annarr þeira: «Enoch heiti ek, ok var ek við Guðs orði hingat fǿrðr.»
German-style quotation marks may also be selected for the display:
Þeir spurðu þá hverir vǽri, „er þit hafið eigi dauðir verit með oss í helvíti.“ Þá svaraði annarr þeira: „Enoch heiti ek, ok var ek við Guðs orði hingat fǿrðr.“
Sometimes, quotation marks appear within quotation marks. The <q> element allows for nesting, e.g.
<q>
<w>This</w>
<w>city</w>
<w>is</w>
<w>called</w>
<q>
<w>Jorvík</w>
</q>
<pc>,</pc>
</q>
<w>he</w>
<w>said</w>
<pc>.</pc>Ideally, the style sheet should display nested quotations with different marks, as in this example (using the Anglo-American style):
“This city is called ‘Jorvík’,” he said.
As stated above, some texts contain quotations. If the encoder wants to identify these, we recommend the <quote> element. This is a new example from Niðrstigningar saga in AM 233 a fol:
. . .
<w>svá</w>
<w>sem</w>
<w>ritat</w>
<w>er</w>
<pc>:</pc>
<quote>
<w>Et</w>
<w>multa</w>
<w>corpora</w>
<w>sanctorum</w>
<w>qui</w>
<w>dormierant</w>
<w>surrexerunt</w>
<pc>.</pc>
</quote>
<note>Matt 27:52</note>The source of the quotation may be given in a <note> element, as shown above.
5.7 Numerals
Numerals are no longer treated as a single word class, in spite of their semantic coherence – they do, after all, convey a number. In line with the word classes proposed in ch. 11.6 below, numerals belong to at least four categories:
| Examples | Word class | Comment |
|---|---|---|
| einn, tveir, þrír, fjórir, ... | Determiners (xDQ) | The word einn can also be adjective (xAJ) |
| fyrstr, annarr, þriði, fjórði, ... | Adjectives (xAJ) | In ONP, see fyrr for fyrstr |
| tigr, hundrað, þúsund | Nouns (xNC) | |
| i, ii, iii, iv, ... | No word class | Recommended @xml:lang="lat" attribute |
Numerals may be encoded by the <w> element throughout. The only specification is that with respect to Roman numerals, there will be no morphological annotation and the delimiters, typically a dot on either side of the numeral, is contained within the <w> element. Examples will be given in ch. 5.7.1 below.
5.7.1 Introducing the <num> element
If an encoder wants to single out numerals, this should be done by the <num> element, irrespective of their form – as Roman numerals, as Hindu-Aarabic numerals (i.e. our “modern” numerals) or spelt out in Latin characters. Note that on the level immediately below, the numeral is encoded within the <w> element.
| Elements & attributes | Obl/Opt | Explanation |
|---|---|---|
| <num> | Contains a numeral, including any delimiters. | |
| @type | Optional | States the type of numeral. Recommended values: |
| ‘cardinal’ | A cardinal number, like “one”, “two”, “three”. . . | |
| ‘ordinal’ | An ordinal number, like “first”, “second”, “third”. . . | |
| @value | Optional | States the actual number in Hindu-Aarabic numerals. Suggested values: |
| ‘1’ | The numeral has the value 1. | |
| ‘2’ | The numeral has the value 2, etc. |
Roman numerals are typically delimited by a dot immediately before and after the number:
Hann er .xij. vetra gamall.
We recommend that these delimiters are encoded as punctuation marks, using the <pc> element within the <w> element:
<w>Hann</w>
<w>er</w>
<num><w><pc>.</pc>xij<pc>.</pc></w></num>
<w>vetra</w>
<w>gamall</w>
<pc>.</pc>Using the optional attributes introduced above, we can specify the type (cardinal or ordinal) and the value (in this case, 12) of the numeral. Note that in the case of Roman numerals, we recommend that the <w> element is supplied by the @xml:lang attribute with the value ‘lat’ (for “Latin”). This makes it abundantly clear whether the single character “i” is a preposition, “in”, or a Roman numeral, “one”.
<w>Hann</w>
<w>er</w>
<num type="cardinal" value="12"><w xml:lang="lat"><pc>.</pc>xij<pc>.</pc></w></num>
<w>vetra</w>
<w>gamall</w>
<pc>.</pc>Hindu-Arabic numerals are found in some medieval sources. They should also be used in the encoding:
<w>Hann</w>
<w>er</w>
<num type="cardinal" value="12"><w>12</w></num>
<w>vetra</w>
<w>gamall</w>
<pc>.</pc>When a number is spelt out in the text, it is encoded as such:
<w>Hann</w>
<w>er</w>
<num type="cardinal" value="12"><w>tolf</w></num>
<w>vetra</w>
<w>gamall</w>
<pc>.</pc>5.7.2 Morphological annotation of numerals
In the case of morphological annotation, the <w> element will receive a @lemma attribute. As stated above, the @type and @value attributes are optional:
<w>Hann</w>
<w>er</w>
<num type="cardinal" value="12"><w lemma="tolf">tolf</w></num>
<w>vetra</w>
<w>gamall</w>
<pc>.</pc>If there is a combination of a Roman and a spelt-out numeral, both will be placed within its own <w> element. Roman numerals should not receive any morphological annotation.
<num type="cardinal" value="7"><w xml:lang="lat"><pc>.</pc>vii<pc>.</pc></w></num>
<num type="cardinal" value="100"><w lemma="hundrað">hundruð</w></num>The examples above show single-level encoding of numerals. In a multi-level encoding, we recommend that levels are specified within the <choice> element, e.g.:
<num type="cardinal" value="4">
<w xml:lang="lat">
<choice>
<me:facs><pc>.</pc>ııı&jnodot;<pc>.</pc></me:facs>
<me:dipl><pc>.</pc>iiij<pc>.</pc></me:dipl>
<me:norm><pc>.</pc>iv<pc>.</pc></me:norm>
</choice>
</w>
</num>In this example, the Roman numeral “iv” is offered as a normalisation of “iiij”, but it might equally well have been “fjórir” or even “4”.
If the numeral is a lexical word, the encoder may want to annotate it. In such cases, the <w> element will be supplemented by the attributes @lemma and @me:msa:
<num type="cardinal" value="4">
<w lemma="fjórir" me:msa="xDQ gM cN">
<choice>
<me:facs>fio&rrot;ir</me:facs>
<me:dipl>fiorir</me:dipl>
<me:norm>fjórir</me:norm>
</choice>
</w>
</num>See ch. 11 for more details on morphological annotation.
5.7.3 Complex numerals
Some numerals are quite complex, especially in the dating of diplomas and other historical documents. We recommend that each constituent is encoded in a <num> element of its own, unless they are non-numerical words. Diplomatarium Norvegicum dates the diploma in vol. 1, no. 80, to “thousand winters and two hundred winters [and] .ix. tens of winters and .ii.”, or, more concisely put, to the year 1292 (DN 1:80):
<num><w lemma="þúshundrað">þushundrað</w></num>
<w lemma="vetr">vetra</w>
<num><w lemma="tveir">tuau</w></num>
<num><w lemma="hundrað">hundrað</w></num>
<w lemma="vetr">vetra</w>
<num><w xml:lang="lat"><pc>.</pc>íx<pc>.</pc></w></num>
<num><w lemma="tigr">tígí</w></num>
<w lemma="vetr">vetra</w>
<w lemma="ok">oc</w>
<num><w xml:lang="lat"><pc>.</pc>í&jacute;<pc>.</pc></w></num>While the noun “vetr” and the conjunction “ok” are part of the whole dating expression, they are not regarded as numerals and not inserted in <num> elements.
Some dating expressions contain Latin words, which should be singled out by the @xml:lang attribute.
5.7.4 Nesting of the <num> element
The <num> element may nest, i.e. that it may contain one or more subordinate <num> elements. A rather simple example would be the one given in ch. 5.7.2 above, in which “.vii. hundruð” amounts to “700”:
<num type="cardinal" value="700">
<num type="cardinal" value="7"><w xml:lang="lat"><pc>.</pc>vii<pc>.</pc></w></num>
<num type="cardinal" value="100"><w lemma="hundrað">hundruð</w></num>
</num>In the example from DN 1:80 above, the whole sequence can be brought together in an overarching <num> element, in which the @value attribute contains the number of the complete dating expression, in this case “1292”:
<num type="ordinal" value="1292">
<num><w lemma="þúshundrað">þushundrað</w></num>
<w lemma="vetr">vetra</w>
<num><w lemma="tveir">tuau</w></num>
<num><w lemma="hundrað">hundrað</w></num>
<w lemma="vetr">vetra</w>
<num><w xml:lang="lat"><pc>.</pc>íx<pc>.</pc></w></num>
<num><w lemma="tigr">tígí</w></num>
<w lemma="vetr">vetra</w>
<w lemma="ok">oc</w>
<num><w xml:lang="lat"><pc>.</pc>í&jacute;<pc>.</pc></w></num>
</num>Datings in diplomas will most likely be given elsewhere in the file.
Many texts contain a large number of words that can be singled out by the <num> element. Þiðriks saga af Bern in Holm perg 4 fol, for example, has a total of almost one thousand <num> elements. Many of these can be nested, but it is an open question whether this additional encoding is worthwhile.
5.8 White space
Note that in XML as well as in HTML encoding, any amount of white space following each other (spaces, tabs and line breaks) are interpreted as a single space. The stylesheets will take care of the correct display of white space, so that there will be a single space between <w> elements, and as a rule after each <pc> element, but not before it, i.e. no space between a <w> element and a subsequent <pc> element. There are some exceptions to the latter rule in connection with quotation marks, which will be handled by the stylesheets, too.
It is not possible to encode a long space in the manuscript
simply by hitting the space bar several times. In our experience, there is no significant variation in word spacing
in Medieval Nordic manuscripts. If, however, a transcriber believes there are more than
one length of the space, the simplest way of encoding this is probably to define the
standard space, 0020, as the default space and to define deviating spaces with
reference to the list of various space lenghts in the Unicode chart General
Punctuation, codepoints 2000–200B. For recommended entities, see the MUFI character recommendation.
Updates to ch. 5
On 21 April 2020, an example was added to ch. 5.3.2 on the multi-level encoding of graphic words such as “veiði kona” for “veiðikona”. The addition extends from “In a multi-level encoding, the word will be transcribed ...” to “... on the <me:norm> level, ‘veiðikona’”.
On 21 June 2020, a new illustration was added in ch. 5.3.1, showing what the text example looks like in the manuscript. This is now ill. 5.4. Furthermore, two illustrations were added in ch. 5.3.2 on the encoding of graphic words such as “veiði kona” and “aveiðiskap”. They have been numered ill. 5.5 and 5.6. Finally, the two final illustrations, which were numbered ill. 5.4 and 5.5, have been renumbered as ill. 5.7 and 5.8.
On 24 June 2020, the description of stylesheets in ch. 5.3.2 was slightly modified.
As of 21 December 2020, we no longer suggest that @hyphen is a suitable attribute to the <c> character, as originally specified in ch. 5.2.3. A hyphen should be regarded as a type of punctuation character and encoded as recommended in ch. 5.5. The latter subchapter remains unchanged.
On 10 February 2021, two examples of multi-level encoding of a numeral were added at the end of ch. 5.7.
On 4 October 2023, the <w> element was included in all examples (also with Roman numerals) in ch. 5.7, the attribute @xml:lang with the value ‘lat’ was recommended for Roman numerals, and an example of a very complex dating was added at the end of the chapter.