Chapter 2. Text encoding using XML
Version 3.0
by Beeke Stegmann, Matthew Driscoll and Tone Merete Bruvik
2.1 What is XML?
XML, Extensible Markup Language, is a recommendation, endorsed by the World Wide Web Consortium, which defines a simple yet flexible generic syntax for document markup. XML, like its predecessor SGML, Standard Generalised Markup Language, developed by IBM in the 1970s and 1980s, allows for the definition of system-independent methods of representing texts of any kind in electronic form.
The term “markup”, originally used for the (hand-written) instructions added to a manuscript or typescript to indicate to the compositor how the printed text was to look in terms of spacing, font size, use of italics and so on, has been carried over into electronic document processing to describe the codes used to indicate these same features and other aspects of processing. A “markup language” is therefore at its most simple a set of codes which are used to indicate or “tag” certain features in the text, normally for formatting purposes. In most modern software packages the markup is generated with little or no conscious effort on the part of the user – in many modern word processing programs, such as the ubiquitous Microsoft Word, the user is not even given the option of viewing the codes. But they are there: and to see just how many one need only open a document produced in, say, Word in a plain text editor such as Notepad. A text of even a few short lines will be prefaced by several dozen lines – possibly even pages – of code.
The problem is that basically every program has its own set of codes, and it is only rarely possible to convert files from one to another without at least some loss of formatting. And it is not just the formatting that goes haywire – many exotic (read non-standard) characters are also likely to mutate or not be displayed at all. SGML was originally developed in order to avoid these problems by being entirely platform independent, hence G for generalised. SGML as well as XML achieve this by identifying the logical elements of the document rather than specifying the processing to be performed on it: the markup is descriptive, in other words, rather than procedural. With descriptive markup, the same document can be processed by many different pieces of software, each of which can apply different processing instructions to those parts of it that are considered relevant.
SGML’s greatest success has been HTML, Hyper-Text Markup Language, the language of the World Wide Web. HTML restricts document authors to a finite set of tags, however, most of which were originally presentationally oriented, and is thus inappropriate for most things other than web design. XML is essentially “trimmed down” SGML. It is not a single, predefined markup language like HTML, but rather a metalanguage desgined for describing other languages. The syntax is essentially still the same as in SGML, but some of the more complex and lesser used options have been removed.
The great advantage of XML is that it brings the power and flexibility of SGML to the Web; an XML document can be marked up entirely in accordance with the needs of the user and the result displayed in a standard web browser (see ch. 2.9 below). The implications for philologists are staggering.
In what follows, most of the more relevant areas of XML markup are touched upon. For a more thorough grounding, one of the many printed handbooks or websites devoted to XML should be consulted. A good place to start would be the World Wide Web Consortium’s own XML pages: http://www.w3c.org/XML/.
2.2 Appearance vs. structure
It is customary, in English and most other Western European languages, to use italic type in texts printed otherwise in plain roman to set certain things off the rest. Hart’s rules for compositors and readers at the University Press, Oxford (39th ed.), for example, stipulates that the titles of books, films, plays, works of art and periodicals (but not chapters, shorter poems, articles) should be printed in italic, as should the names of ships (but not public houses), words and short phrases in foreign languages (other than those, such as quiche and blitzkrieg, that have been sufficiently anglicised so as to render this unnecessary), stage directions in plays, theorems in mathematical works and biological and zoological nomenclature. Although Hart’s does not mention it, italic font is also regularly used to indicate emphasis, for example in novels: “I most certainly didn’t ask him to come.” With ordinary word-processing softwares, all these things would be marked up directly, i.e. with the relevant codes for “italic-on” and “italic-off”. If you think of the computer as a glorified typewriter and are only interested in producing copies with the correct formatting, fine. If you wish to take advantage of the possibilities offered by sophisticated information retrieval systems, however, you are in trouble, since a search engine will not be able to distinguish foreign words from book titles or the names of ships, for the simple reason that procedural markup such as that produced by ordinary word-processing software only indicates how something is to be displayed, but not why is it to be displayed that way. With descriptive markup, on the other hand, elements in the text are tagged according to their function, e.g. as titles, names, foreign words or stage directions. These can then be processed in whatever way one desires, for example displayed in italics. By concentrating on the structure of the document rather than its appearance a great many possibilities are opened up. Elements in the text can be marked up even where one has no desire to format them in any special way. One might wish, for example, to tag the names of persons, so that a search for “King George”, for example, would turn up only persons of that name rather than vessels or public houses.
2.3 Elements
The key concept in XML markup is the element. An element is essentially a textual unit, the idea being that texts, like houses, are made up of repeated occurrences of basic units arranged in a hierarchical structure; longer works in prose will be divided into chapters or sections, and these into sub-sections and then further into paragraphs or words. There also may be lists and tables. Works of poetry may be divided into cantos or fits, and these into stanzas, and the stanzas into couplets, the couplets into lines, the lines into feet etc. The individual sections, whether chapters or cantos, will often have headings, which are not strictly speaking part of the main text, but nevertheless belong with it. Moreover, these elements will only combine in certain ways. A chapter will not begin in the middle of a paragraph, for example, or in a footnote.
In XML pairs of tags are used to mark off such units, a start tag and an end tag, with the text in between being referred to as the element’s content. Corresponding start and end tags have the same “name” that ist placed within angle brackets, with a solidus to indicate an end tag. Chapters in a book, for example, could be understood as separate divisions and accordingly demarcated by placing a <div> tag (short for division) at the beginning of each one and a corresponding </div> tag at the end. Within each division there would be any number of paragraphs, usually tagged with <p>. Since XML is structured hierarchically, elements can contain each other, but only in their intirety. Overlapping structures of elements are not allowed (instead, so-called milestones (empty elements) are used; see ch. 3.12 below and, in general, ch. 16 below).
The way two elements relate to each other hierarchically is determined by the schema used, which in our case would stipulate that a <chapter> must contain one or more <p> elements. In any given schema, there is a declaration for each element enumerating what other elements it may or must contain, how many of each, and if there are any constraints on the order. The more elements one has in one’s system the more complicated, and subtle, that system becomes. (For more details on the schema see ch. 2.6 below.)
To examplify the use of elements, let us have a look at how to markup the structure of the two first stanzas of the Eddic poem Þrymskviða, rendered in normalised orthography. The text is based on the edition by Jón Helgason (1955) and the translation is the one by Carolyne Larrington (1996):
Reiðr var þá Vingþórr Ok hann þat orða | (Thor was angry And these were the first words |
The structure of this poem is clear enough: it is made up of two stanzas each of which contains eight short lines. This structure could be marked up in the following way:
<text xml:lang="en">
<body>
<lg>
<l>Reiðr var þá Vingþórr</l>
<l>er hann vaknaði</l>
<l>ok síns hamars</l>
<l>um saknaði,</l>
<l>skegg nam at hrista,</l>
<l>skör nam at dýja,</l>
<l>réð Jarðar burr</l>
<l>um at þreifask.</l>
</lg>
<lg>
<l>Ok hann þat orða</l>
<l>alls fyrst um kvað:</l>
<l>Heyrðu nú, Loki,</l>
<l>hvat ek nú mæli,</l>
<l>er eigi veit</l>
<l>jarðar hvergi</l>
<l>né upphimins:</l>
<l>áss er stolinn hamri!</l>
</lg>
</body>
</text>
Note that in this example, standard TEI elements are used: <text>, <body>, <lg> (short for “line group”, marks a stanza), and <l> (the element that marks an individual line). For more details on encoding standards and TEI see ch. 2.8 below.)
If we abstract from this and attempt to describe the structure of poems in general we could say that a poem consists of one or more stanzas (<lg>) each of which is made up of one or more lines (<l>). A poem will also normally have a title and be attributable to an author (even if that author – as in the case of Þrymskviða – is the highly prolific “Anon.”). The name of the author will obviously not always appear with the text of the poem, however, for example in a series or collection, where there are several poems by the same author. Therefore, we might want to allow our <body> element also to contain, let us say, <title> and <author>. Additional elements would further be required if more than one poem were to be transcribed but still marked as separate works, for example in a <collection> of poems. If one envisaged this collection as an anthology, one would probably wish to divide it into sections, in which poems by a particular poet were grouped together; in the case of Eddic poems, one might make a division between mythological poems and heroic lays. Each of these sections would have a heading and possibly some prefatory matter, giving information on the author. Like that, virtually any level of structural hierachy can be marked using XML elements if they are employed systematically.
Other elements used in XML markup have less to do with the overall hierearchical structure of the text or document and are more free-floating, i.e. can appear in a variety of contexts, or in XML language: can be contained by a variety of elements. Such elements, often referred to as phrase-level elements, are usually more content-related. Besides being able to render tagged contents in any given way, the principal use of elements and markup is to enable searches: Anything that is marked-up can be searched for later. One might, for example, wish to markup all names in the poem above. The personal name “Vingþórr” in line one of our poem could then be tagged with an element we call <name>:
<l>Reiðr var þá <name>Vingþórr</name></l>2.4 Attributes
Without further information, the usefulness of such tagging is sometimes limited. More specific information about a particular element instance can be given as a so-called attribute. Looking at the stanzas just cited, one might, for example, want to add attributes to individual elements, using convenient typologies to indicate number, genre, form, metre or rhyme-scheme. The elements <lg> and <l>, denoting stanzas and lines, could for instance be described in more detail by adding an attribute for the number: @n. One ore more attributes are added to the opening tag of elements in such a way that they follow the element name, separated by a white space. The value of an attribute is given in double quotations to the right of an equals sign. Adding a @n attribute (with the value ‘1’) to the <l> element of the first line would be encoded like this:
<l n="1">
Reiðr var þá <name>Vingþórr</name>
</l>
It might further be an advantage to indicate the type of name in order to distinguish personal names from the the names of places, ships, swords etc.:
<l n="1">
Reiðr var þá <name type="person">Vingþórr</name>
</l>
Attributes are very useful for search and processing purposes, because they allow additional degrees of abstraction. Like elements, they are declared in the schema, where a list of possible attributes or kinds of attributes is given for each element. It is also possible to specify what type of value is acceptable for each attribute, as well as a default value if that is desired.
2.5 Entities
The aspects of XML discussed so far are all concerned with the markup of elements within the
document. XML also provides a mechanism for encoding and naming parts of the document’s
content: through entities. An entity is a kind of shorthand, a way of stating that when the
document is processed, a particular string of characters in the document should be replaced by
some other string. This other string can be of any length, from a single character to a
separate file containing millions of bytes, such as a text file or digital image. When using an
entity, the name of that entity (entity reference) is placed between an ampersand and a
semicolon: &entityname;. Only entities that have been declared can
be processed by the application.
A single declaration for a general entity looks like this:
<!ENTITY vth "Vingþórr">This entity declaration instructs the processing
software (a parser or browser) to
replace any entity reference &vth; it encounters in the XML file
with the text “Vingþórr”.
In the case of our single
poem, there is obviously no real advantage to treating the name of
the protagonist in this way, but in longer documents or collections of
documents it can be an extremely efficient way of dealing with
repeated content.
Entities may also contain XML markup (provided it is well-formed) as well as text:
<!ENTITY vth "<name type='god' subtype='áss'>Vingþórr</god>">An entity can further refer to an external file, as in the following example:
<!ENTITY chapter1 SYSTEM "chapter1.xml">Such entities are called system entities: instead of the replacement text, the declaration gives a “SYSTEM” keyword and a relative or absolute URL. The processing software will then replace the entity with the document found at the address given, i.e. insert that document into the existing document. The resulting document must be well-formed XML, so one must ensure that the document to be inserted is itself well-formed (although it need not have a single root element) and does not for example contain a prologue (i.e. XML and/or DOCTYPE declaration).
A third type of entities are called parameter entities; these are used inside markup declarations and need not concern us here.
For our purposes entities are particularly useful for providing descriptive mappings for
non-standard characters, such as characters used in medieval manuscripts. There are standard
mappings for commonly used characters, such as from the western-European languages (e.g.
ISOlat1 and ISOlat2), as well as character sets for Greek (ISOgrk1), Cyrillic (ISOcyrl1) and
other alphabets. The Unicode Standard, a character coding system desigend to support worldwide
interchange, processing and display of written text, covers most of the world’s languages,
living and dead, and also allows for user-defined characters. The current version 12.0 contains
a total of 137,928 characters (released March 5 2019). Each of these characters is
assigned a unique code point, which can be encoded in a variety of ways. The most common format
is UTF-8, but the numeric value of the code points can be used to encode characters as
entities. Such numerical character references can be either decimal or hexidecimal; decimal
references begin with an ampersand and the number sign, also called hash mark (#), to which
hexidecimal references add an x. For example, the Unicode hexidecimal character reference for
the letter “ę” is ę, while the decimal
reference is ę. These standardised numerical character
references are supported by standard browsers and do not need to be defined as additional
entities. However, one may prefer to use human readable entities for such characters which are
not available on the keyboard used, or for reasons such as proof-reading. Instead of the code
point, one can, for example, use the entity ę for
“ę”. It is a simple matter to define characters as general entities, giving the
numerical character reference as the replacement text:
<!ENTITY eogon "ę">In fact, all characters in the official part of the Unicode Standard can now be entered directly from the keyboard. See ch. 5.2.2 for more details on this.
Even more specialized characters might not be defined as part of the Unicode Standard – yet – and thus have to be defined as entities. For instance, the producer of a diplomatic text edition might want to distinguish between single and two-storey a. The encoder could achieve this by using two different entities, but with the same replacement text. That would make both variants appear identical when displayed, but they would be available for search purposes. More commonly, an encoder wants to retain and also show certain features of the medieval script, as they are potentially relevant for the reader. This is possible as long as suitable characters have been defined. Frequently, however, such specialized characters are only avaialble as part of a non-standard font, for which the characters are mapped in the so-called Private Use Area (PUA). Such character references are not supported by standard browsers as they can be different for each font. Instead, they need to be referenced, which is best done with entities.
Special characters useful for Old Norse are created, for instance, by the Medieval Unicode Font Initiative (MUFI). The most commonly used ones have been compiled by Menota into a list of entities, mapping them to their Unicode PUA values (see also ch. 5.2.2). This Menota entity list is available as an external file, which can conveniently be referred to from any XML document using a system entity:
<!ENTITY % Menota_entities SYSTEM
'https://www.menota.org/menota-entities.txt'>
%Menota_entities;]>In recent years, the TEI community has moved towards the use of the <g> element (for “gaiji”, Japanese for ‘external character’) in order to encode non-standard characters. So rather than, for example, using an entity like &ocurl; for the character “”, one might encode it as e.g. <g ref="#ocurl"/> using the gaiji module, as described in the TEI Guidelines P5, ch. 5.2.
This requires an extensive <charDecl> section in the header of the document defining each “gaiji” character.
As can be seen throughout the chapters in this handbook, we use the tested and tried mechanism of character entities for the large number of non-standard characters. These entities will be introduced in ch. 5, and an abundance of them will be found in e.g. ch. 6. For Menota files, it remains the fastest and simplest option of encoding non-standard characters. As stated above, these characters are defined in a single document, the text file called menota-entities.txt. Like the schemas needed for the validation of the Menota file, this text file is located at the Menota repository, presently held at the University Library in Bergen. If a new entity is added to this file, it can immediately be used by all Menota XML files without any further declarations – for the &ocurl; entity, for example, only a single line is required:
<!-- LATIN SMALL LETTER O WITH CURL --> <!ENTITY ocurl "">In this example, the entity is referring to a codepoint in the Private Use Area, which can be seen from its hexadecimal value, E7D3. If this character at a later stage is admitted into the official Unicode Standard (and that has indeed happened with a number of the Medieval Nordic characters) one only has to change the hexadecimal value in this line, and it will be applicable to all Menota XML files.
The menota-entities.txt file can be downloaded in app. D.1.1 (2) below.
2.6 The Text Encoding Initiative and TEI conformant schemas
The most widely used XML implementation for more sophisticated text encoding is that devised by the Text Encoding Initiative (TEI), an international and interdisciplinary standard for the preparation and interchange of electronic texts. The TEI began with a planning conference which took place at Vassar College in New York on 12-13 November 1987. The participants agreed on both the desirability and feasibility of creating a common encoding scheme for use in creating new documents as well as in exchanging existing documents among text and data archives. The TEI thus began the task of developing a draft set of Guidelines for Electronic Text Encoding and Interchange, with working committees comprising scholars from all over North America and Europe drafting recommendations on various aspects of the problem. These were integrated into a first public draft, TEI P1 (P for “Proposal”), published in June 1990. A second draft (TEI P2) followed in 1992 and 1993, and the first official version of the guidelines (TEI P3) was published in May 1994. The next version, TEI P4, was released in June 2002. On 1 November 2007, TEI P5 was released in electronic form only at TEI Guidelines. The present version of the Menota handbook is conformant with TEI P5.
The TEI began as a research effort cooperatively organised by three scholarly societies (the Association for Computers and the Humanities, the Association for Computational Linguistics, and the Association for Literary and Linguistic Computing), and funded by research grants from the US National Endowment for the Humanities, the European Union, the Canadian Social Science Research Council, the Mellon Foundation and others. In December 2000, after a year’s negotiation, a new non-profit corporation called the TEI Consortium was set up to maintain and develop the TEI standard. Four universities serve as hosts for this consortium, presently two in the United States and two in Europe. The Consortium is managed by a Board of Directors, and its technical work is overseen by an elected Council. There are numerous projects currently using the TEI encoding scheme, Menota being one of them.
TEI offers several schemas for defining the structure of an XML file. The schema restricts the elements allowed both in terms of their content, their attributes and relationship to each other. One of the great strengths of using TEI conformant schemas is that they provide of a number of different tag sets which can be used in a variety of combinations, according to the needs of the encoder and nature of the material being encoded. The encoder can either use the very general TEI schema with a large number of elements and attributes, or pick and choose from it by selecting only the ones relevant to the material to be encoded, thus tailoring the schema to his or her individual needs. The Menota schema is an example of the latter, containing a specialized subset of the elements defined in the general schema (with the addition of some local elements and attributes).
In TEI P4 and earlier releases, the only schema was the Document Type Definition (DTD) mentioned above. As of TEI P5, a RELAX NG (RNG) schema has been added. We offer schemas of both types in app. D.1.1 (3) and (4) to this handbook, but recommend to use the RNG schema. The function of a RNG schema is the same as that of a DTD, but it allows users to make a clear distinction between TEI elements and attributes on the one hand and local elements and attributes on the other hand by way of establishing a namespace. Consequently, the encoding becomes more transparent. (The concept and possibilities of a namespace is explained in ch. 2.8 below.)
A schema, as was said, defines the structure of the document, and is thus like a grammar, detailing the elements which can appear in the text and their hierarchical relationship to each other. In order to ensure that this is done correctly, every encoded text needs to be checked against the schema, if there is one, or checked for “well-formedness” if there is not. A computer program called a parser runs through the encoding and gives an error message if there are errors or inconsistencies in the markup, e.g. if elements are not opened and closed correctly, or used in the wrong place, or if elements overlap. If the elements in a document are correctly opened and closed, and non-overlapping, the document is called well-formed. A parser can determine “well-formedness” without recoursing to a schema. If, in addition, the content types of elements, the nesting of elements and the use of attributes are all done according to the specification of the schema, then the document is not only well-formed, but also valid.
Validation only checks the markup – not the content – of the document. A document can consist entirely of gibberish and still be valid – as, indeed, can a document with no content at all. The correctness of the contents remains the responsibility of the transcriber.
XML-aware software, such as <oXygen/>, SoftQuad’s XMetaL or XMLSpy, generally comes with a built-in validator (see app. C for different XML editors). Separate validator programs are also available.
2.7 Putting the pieces together
The first line of our XML document is the XML declaration, which tells any processing software that the document is in XML:
<?xml version="1.0" encoding="UTF-8"?>The @version attribute is required and the standard version is currently ‘1.0’, but it is possible that there will be further versions in the future. Two more attributes are optional: @encoding, which specifies which encoding is to be used (the variable length encoding of the Unicode character set, UTF-8, is assumed by all the standard browsers), and @standalone, the possible values for which are ‘yes’ and ‘no’ to specify if the document makes use of an external schema. XML documents do not in fact require a schema, provided they are “well-formed” (see below), but in most cases it is adventageous to employ a schema. In cases where there is no schema the value of the @standalone attribute should be ‘yes’. If the attribute is omitted, on the other hand, the default value ‘no’ is assumed.
The document’s second line, following the XML declaration, is the reference to the schema used. In the handbook, we offer two closely related schemas, a Document Type Definition (DTD) schema and a RELAX NG schema. As of v. 3.0 of the handbook we recommend to use the RELAX NG schema, which is more flexible, yet at the same time somewhat stricter than a DTD. The main difference, however, is that the (older) DTD schema cannot handle multi-level transcriptions using the Menotic elements <me:facs>, <me:dipl> and <me:norm> (see also app. D).
The Menota schema is designed to cover the relevant elements needed for encoding Old Norse texts. Its usage is strongly recommended for producing transcriptions or other documents according to the standards described in this handbook. The schema is available online and can be referred to in the schema declaration (internet access required) using the URL “http://www.menota.org/menotaP5.rng”. It can be downloaded from app. D.1.1 (4). An external RELAX NG schema, in this case the current Menota schema, is referenced like this:
<?xml-model href="http://www.menota.org/menotaP5.rng"?>Some XML editors additionally have their own way of referencing external schemas, but the neutral code given above should work in any event. Here is an example of a editor specific reference to the same schema (in this case <oXygen/>):
<?oxygen RNGSchema="http://www.menota.org/menotaP5.rng" type="xml" ?>Following the schema, the entities used in the document are referenced. Entities can either be defined manually or provided by means of external entity lists, for instance as a system entity (see ch. 2.5.) After that – finally – the proper XML code follows, which is then supported and checked against the data provided by the schema and entities.
A structured XML document contains different kinds of components. We have already learned about elements, containing text, and thus the actual contents. We have also seen that elements can have one or more attributes with their various values. Finally, XML documents may also contain comments. Comments begin with “<!--” and end with “-->”. They are allowed anywhere in the document (but not before the XML declaration), as long as they are outside other markup, i.e. not within a tag. Any markup or contents inside a comment is considered as not actually part of the document – it is “commented out” and ignored by the parser. Comments are particularly useful for anyone working in XML who wants to make a note to him or herself or others without it being processed.
All TEI conformant documents have as their outermost element (the so-called root element) the <TEI> element. Inside of the <TEI> element there must be two elements, a header, tagged <teiHeader> (see ch. 14), and the text itself, tagged <text>. The <teiHeader> contains meta-data, i.e. information about the electronic document provided, and the <text> contains the actual contents of the document. What elements go into the <text> is to a great extent determined by which base and additional tag sets have been chosen in the schema.
In addition to purely structural elements such as the ones used in the markup of our stanza above, the TEI also makes available a host of elements for indicating features of typography and layout. Although these were originally intended for use in the description of printed materials, most if not all are equally applicable to manuscripts. There are also tags which can be used for normalisation, grammatical information etc. The other chapters in this handbook explain in detail how they can be used.
2.8 The namespace: Adding elements and attributes
In this handbook, we are following the recommendations in the TEI Guidelines P5 closely. We have, however, introduced a few additional elements and attributes in order to enhance the encoding of Medieval Nordic manuscripts (and, we believe, other medieval manuscripts). According to TEI P5, any additions of this type should be defined as a namespace, and we have consequently set up a namespace “me” for our usage (“me” being short for “Menota”).
Namespaces are specified at the very beginning of the XML code, in the case of TEI-conformat XML as an attribute to the <TEI> element:
<TEI xmlns="http://www.tei-c.org/ns/1.0" xmlns:me="http://www.menota.org/ns/1.0">
...
</TEI>In the Menota XML files, all additional elements and attributes will be preceded by “me:”. For example, we recommend that a normalised transcription is contained in such an additional element, which we call norm. It appears as <me:norm>, where the prefix identifies it as an element belonging to the Menota namespace. The advantage of doing this, is that all additional elements and attributes stand out clearly in the encoding; anyone who just glances through a Menota XML file will understand which elements and attributes belong to TEI P5 and which are the additions by Menota.
The following is a complete list of additional elements and attributes in The Menota handbook:
2.8.1 Elements
<me:facs> for readings on a facsimile level, cf. ch. 4.2.
<me:dipl> for readings on a diplomatic level, cf. ch. 4.3.
<me:norm> for readings on a normalised level, cf. ch. 4.4.
<me:pal> for readings on a paleographical level, cf. ch. 4.6.5.2.
<me:suppressed> for readings that are deleted by the editor (as opposed to deletions by the scribe, which are encoded by the <del> element), cf. ch. 9.3.2.
<me:textSpan/> for encoding any discontinous structures, thus avoiding a full set of elements like <addSpan/>, <delSpan/>, <suppliedSpan/>, <suppressedSpan/>, etc. Note that the attribute @me:category is used to specify what type of textspan it is, i.e. an addition, deletion, supplement, suppression, etc., cf. ch. 16.2.
<me:all> for alliteration in encoding of verse, cf. ch. 13.2.
<me:ass> for internal rhyme in encoding of verse, cf. ch. 13.2.
2.8.2 Attributes
@me:msa for morphosyntactical analysis, i.e. for specifying the grammatical form of a word. This is an attribute to the <w> element, cf. ch. 11.3.
@me:type for classification purposes. This is an attribute to the <ex> and <am> elements, cf. ch. 6.1.
@me:key for linking to another resource which describes the thing(s) the element references (e.g. person, text, place, word, etc.), in the form of a database key or similar, used as an attribute to a number of elements, cf. ch. 15.2.2.
@me:ref for linking to an external resource which describes the thing(s) the element references (e.g. person, text, place, word, etc.), in the form of one or more URIs or similar identifiers, cf. ch. 15.4.1.
@me:level for identifying the level on which the text has been transcribed, i.e. facsimile, diplomatic or normalised (see above). This is an attribute to the <normalization> element used in the header, cf. ch. 14.4.
@me:lemmatized for identifying those texts which have been lemmatised. This is an attribute to the <interpretation> element used in the header, cf. ch. 14.4.
@me:morphAnalyzed for identifying those texts which have been morphologically analysed, i.e. given grammatical form. This is another attribute to the <interpretation> element used in the header, cf. ch. 14.4.
@me:category for identifying the type of a text span. This is an attribute to the <me:textSpan/> element used to encode overlapping structures, cf. ch. 16.2.
2.9 Displaying the text
We have mentioned several times the possibility of displaying XML documents in standard web browers. In order to do so, one final piece is necessary: a stylesheet. As has been said, XML elements describe, ideally at least, the semantic structure of the text, rather than its appearance (although there is obviously a degree of overlap). Web browsers have built-in stylesheets for displaying HTML and know that in an HTML document anything tagged <i> is to be displayed in italic. XML markup is semantic (and the elements in principle user-defined), and in order for a browser to display an XML document, it needs to know what formatting to apply to what elements. It needs to be told, for example, that things within <title> tags should be displayed in italic. A stylesheet does precisely that.
There are essentially two options, Cascading Stylesheets (CSS) and Extensible Stylesheet Language Transformations (XSLT). CSS is a simple, non-XML syntax used to describe the appearance of any element in a document and widely in combination with HTML. XSLT, on the other hand, is itself an XML application which specifies rules by which the XML document is transformed into another document. The output can be in different formats, among others another XML document, but for displaying purposes its most obvious use is to tranform the existing XML document into something more browser-friendly such as HTML (or XHTML). Doing that, the original document retains its complexity, while for viewing purposes it is changed into something browsers can deal with. This transformation can be done by the browser when the XML document is called up by the user; by a web server applying the transformations before serving the document; or by the creator of the document, who may not wish to make it available in its orginal state.
A stylesheet can be associated to an XML document in several ways. Most standard XML editors offer for example functions to set up personalised transformation scenarios, which apply a selected stylesheet to any given XML input and open the results in a Web browser. Easier to use might be an XSLT stylesheet processing instruction (also called “stylesheet link”), which is simply inserted at the top of the document, i.e. in front of the root element, similar to a RNG schema reference. The @href attribute of this processing instruction refers to the absolute or relative location of the stylesheet that is supposed to be associated, and depending on the stylesheet format used, the @type attribute must be set to "text/css" or "text/xsl". There are other (pseudo-) attributes, such as @media, but they need not concern us here (For instructions on how to apply an XSLT stylesheet see also app. F). The first example shows a local reference to a CSS stylesheet, while the second associates an XSLT stylesheet from the web with the XML file in question:
<?xml-stylesheet href="poem.css" type="text/css"?>
<?xml-stylesheet href="http://www.menota.org/menota_xslt_3_dipl.xsl type="text/xsl""?>The CSS stylesheet referred to in the first example was desgined for the markup of the poem used above. It indicates how each of the elements is to be displayed (using the CSS language):
body {
font-family: "Book Antiqua";
}
body {
display: block;
font-family: "Book Antiqua";
margin: 25pt 15pt 15pt 45pt;
font-size: 13pt;
line-height: 15pt}
title {
display: block;
font-size: 18pt;
padding: 5pt}
author {
display:none;}
lg {
display: block;
padding: 5pt}
l {display: block}
name {font-style: italic}Displayed by an XML-aware browser, such as Firefox (Windows, Mac, Linux), Google Chrome (Windows, Mac, Linux), Safari (Mac), the two first stanzas of Þrymskviða will be displayed as in Fig. 2.1.
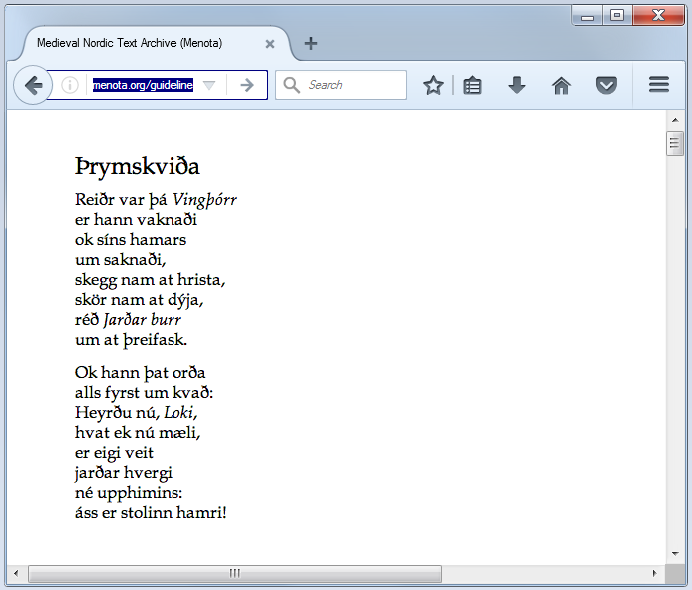
Ill. 2.1. Screen display of the first two stanzas of Þrymskviða.
Note that browsers may display the same page slightly differently. If it does not look right in one browser, another browser may do the trick.
XSLT is more powerful than CSS. With CSS one can determine exactly how the content of an element is to be displayed, in terms of font, colour etc., or whether it is to be displayed at all (one might not, for example, wish to display some of the administrative information contained in the TEI header). CSS will also allow you to insert text before and/or after an element (using the before and after pseudo-element selectors). But that is about it. With XSLT, on the other hand, one can, for example, re-arrange the order of the elements or display the value of an element’s attribute instead of its actual content. For the actual styling of the (re-arranged) content, XSLT ultimately uses the CSS language (either built in to the same document of pulling from a separate file), meaning that with XSLT one has all the options of plain CSS in addition to powerful transformations.
The above display of an Eddic stanza is the preferred one in many Nordic editions; each line occupies a line in the edition, whether it is a short line (as in fornyrðislag) or a full line (as in ljóðaháttr). In Continental and British/American editions such as the classic edition by Neckel/Kuhn (1983), a pair of short lines making up a long line is printed as a single line in the edition, though with a sizeable space between the two lines, thus:
Reiðr var þá Vingþórr er hann vaknaði
ok síns hamars um saknaði
skegg nam at hrista, skör nam at dýja,
réð Jarðar burr um at þreifask.
For ease of reference, lines are numbered, but in stanzas of normal length only each fourth line (in ljóðaháttr) or each fifth line (in fornyrðislag) are numbered. In an eight-line display such as the one in the screenshot above, the fitfth line of the first stanza is the one beginning with “skegg”. The same applies to the four-line display above, since each short line is counted, irrespective of whether it is displayed in conjunction with another short line or not. To achieve a “Neckel/Kuhn display” two operations are necessary, (a) every second short line in the encoded text is displayed on the same line as the previous short line, and with white space in between, and (b) lines are counted and a small number is positioned in the margin in front of every fifth line. This adds an element of transformation to the styling that can be performed in CSS using the :nth-child() selector. In XSLT this is quite simple, even if the instructions may look difficult. An XSLT stylehseet transforming the text as specified in (a) and (b) would look like this:
<xsl:template match="lg">
<table class="stanza">
<xsl:for-each select="child::l[ position() mod 2 = 1]">
<tr>
<xsl:choose>
<xsl:when test="attribute::number mod 5 = 1">
<!-- The first line -->
<td>
<xsl:value-of select="parent::lg/attribute::number"/> . 
</td>
</xsl:when>
<xsl:when test="attribute::number mod 5 = 0">
<!-- Line 5 -->
<td>
<xsl:attribute name="class">small</xsl:attribute>
<xsl:value-of select="attribute::number"/>
</td>
</xsl:when>
<xsl:otherwise>
<td></td>
</xsl:otherwise>
</xsl:choose>
<td><xsl:apply-templates/>  
<xsl:apply-templates select="following-sibling::l[1]"/>
</td>
</tr>
</xsl:for-each>
</table>
</xsl:template>
Displayed in an XML-aware browser, the stanzas now look like Fig. 2.2 (still also using most of the CSS styling specifications from above).
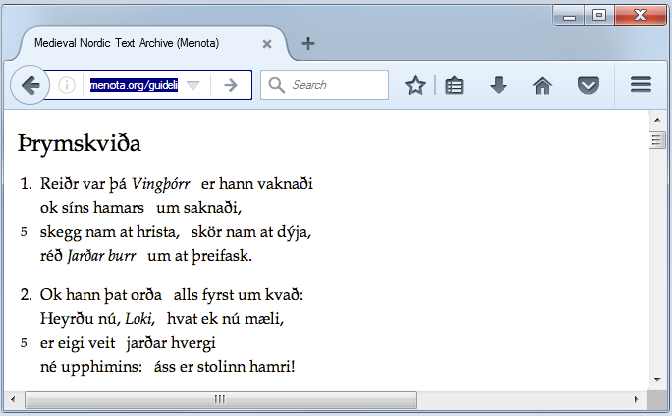
Ill. 2.2. Alternative screen display of the first two stanzas of Þrymskviða.
The display is different, but the XML encoding is not changed at all. It is only a matter of transforming the encoded text using XSLT and adding the required style with CSS. An XML document can also be transformed into a non-XML format, for example, plain text, a PDF, RTF or PostScript file. And the same XML file can be transformed again and again into dozens of different formats.
2.10 Menotic stylesheets
Menota makes available XSLT stylesheets that have been optimised for displaying digital transcriptions that were produced according to the guidelines of this handbook. The stylesheets as well as an introduction to how to apply them are found in app. F. The latest version of the XSLT (for the present version of the handbook) now allows for sophisticated display of many manuscript-specific features on the facsimile level, such as multi-part rubrics and scaled initials. Please bear in mind, however, that preference was given to incorporate features that were deemed essential and less common features or special cases might not be rendered correctly – yet – even though they are encoded in accordance with the handbook’s recommendations.