Appendix: MenotaBlitz.html manual
Version 0.9.9 (11 April 2021)
edited by Robert K. Paulsen.
Introduction
This is a torso of the full MenotaBlitz.html Manual, planned and edited by Robert K. Paulsen. At the moment, it is not complete yet, only containing preliminary chapters 3 (Ekaterina Vybornova), 4.1 (Paola Peratello), 4.4 (Robert K. Paulsen), 4.6 (Valerio Nazario Rossetti), 4.7 (Odd Einar Haugen), 4.8 (Patrick Farrugia), and 4.9 (Tonje Waldersnes). Remaining chapters will be added in due course of time.
MenotaBlitz.html is a tool for the simple transcription of primarily Old Norse source material and the easy production of Menota-compatible XML files.
1. The Website
2. Navigation
3. Metadata
by Ekaterina Vybornova.
This chapter explains how basic Metadata about the encoder and the text are entered into the Menota interface. Note that a more detailed description of the source text as well as further information about people involved can be given in the header of the finished Menota XML file (see Ch. 14 The header of Menota-handbook) after exporting one's transcription (see Ch. 5 of this documentation).
| Field | Explanation |
|---|---|
| Your name | Here you, the transcriber, can record your full name. |
| Affiliation | Here you type in the name of a relevant institution you are affiliated with, e.g. the university, library or museum you work or study at. |
| Artefact type | Choose one of two possibilities: “Manuscript” (also for charters, letters, and fragments) or “Runic inscription”. |
| Shelfmark (signature) | Here you enter your artefact's unique identifier, i.e. its shelfmark (e.g. “AM 242 fol.”), signature, or catalogue number (e.g. “N 288”), depending on the type of the artefact. |
| Artefact name | Many artefacts have inofficial nicknames, making them easier to talk about. This is especially true for manuscripts (“Codex Wormianus”, “Morkinskinna”), while runic inscriptions may often be identified by where they were found (“Bryggen inscription”, “Eggjar stone”) or people that are mentioned (“Ingibjǫrg inscription”). |
| Collection | Here you enter the name of the institution that keeps your artefact, be it a library, a museum, or a private collection. Leave this field (and the following two) empty if your artefact has been lost and thus is no longer located anywhere. |
| City | The city or settlement your artefact is located in (not where it was found!). |
| Country | The country your artefact is located in (not where it was found!). |
Сompletely filled out metadata fields for a manuscript and a runic inscription may look like this:
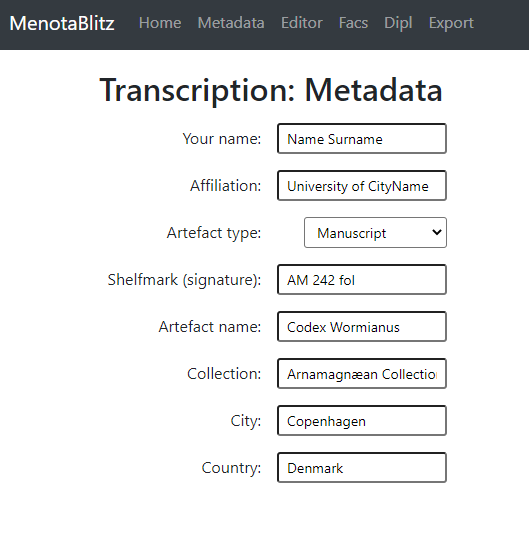
Ill. XXX. Metadata for a manuscript (AM 242 fol).
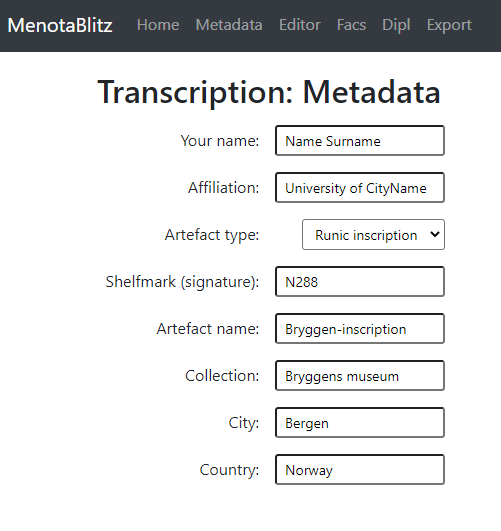
Ill. XXX. Metadata for a runic inscription (N 288).
4. Transcription
MenotaBlitz.html has a transcription section containing an editor where the transcriber can enter the actual transcription of the source material. In order for the program to interpret the transcription correctly, it has to be carried following a specific transcription standard: MenotaBlitz Code (MBC). The following chapter describes how to transcribe manuscript material according to this standard and what the Menota XML produced by it would look like.
4.1 Document structure
by Paola Peratello.
In MBC, document structure is encoded using the following tags:
{div} ... {/div} | “division”: These mark the beginning and end of higher level
document structures, such as the text itself, sections, or chapters. div tags may be nested within one another. |
{p} ... {/p} | “paragraph”: These mark the beginning and end of paragraphs and are
only permitted within {div} ... {/div} tags. Multiple
p elements are permitted within the same div element, but p elements may
not be nested within one another. |
{head} ... {/head} | “head”: These mark the beginning and end of chapter headings. A head element may only be used at the very beginning of
a div element. There may never be more than one head element within the same div element and head elements may not be
nested within one another. |
Note that all transcribed text must be
enclosed within either a p or a head
element!
Thus, the following is the correct hierarchical order of the above listed elements:
{div}
{head} ... {/head}
{p} ... {/p}
{/div}

Ill. XXX. SKB A 120, fol. 1r.
In the case of a fragment starting in medias res, {head} is not used: instead, {div} is followed by
{p}. For instance, the first two lines of fol. 1r from
can be encoded in MBC as follows:
{div}
{p}
:1r:
:1: g : i : himiriki : gesus :
kruzifiz:2:sus : miild : moþær : te : mik : þæt : iak :
{/p}
{/div}Upon export, this will result in the following Menota XML:
<div>
<p>
<pb ed="ms" n="1r"/>
<lb ed="ms" n="1"/>
<w>
<choice>
<me:facs>&gMD;</me:facs>
<me:dipl>g</me:dipl>
</choice>
</w>
<pc>
<choice>
<me:facs>&twodotPM;</me:facs>
<me:dipl>:</me:dipl>
</choice>
</pc>
<w>
<choice>
<me:facs>&iGE;</me:facs>
<me:dipl>i</me:dipl>
</choice>
</w>
<pc>
<choice>
<me:facs>&twodotPM;</me:facs>
<me:dipl>:</me:dipl>
</choice>
</pc>
<w>
<choice>
<me:facs>&hYGL;&iGE;&mYGL;&iGE;&rGE;&iGE;&kYG;&iGE;</me:facs>
<me:dipl>himiriki</me:dipl>
</choice>
</w>
<pc>
<choice>
<me:facs>&twodotPM;</me:facs>
<me:dipl>:</me:dipl>
</choice>
</pc>
<w>
<choice>
<me:facs>&gMD;&eMD;&sYGL;&uGE;&sYGL;</me:facs>
<me:dipl>gesus</me:dipl>
</choice>
</w>
<pc>
<choice>
<me:facs>&twodotPM;</me:facs>
<me:dipl>:</me:dipl>
</choice>
</pc>
<w>
<choice>
<me:facs>&kYG;&rGE;&uGE;&zMDsht;&iGE;&fGE;&iGE;&zMDsht;<lb
ed="ms" n="2"/>&sYGL;&uGE;&sYGL;</me:facs>
<me:dipl>kruzifiz<lb ed="ms" n="2"/>sus</me:dipl>
</choice>
</w>
<pc>
<choice>
<me:facs>&twodotPM;</me:facs>
<me:dipl>:</me:dipl>
</choice>
</pc>
<w>
<choice>
<me:facs>&mYGL;&iGE;&iGE;&lGE;&dMD;</me:facs>
<me:dipl>miild</me:dipl>
</choice>
</w>
<pc>
<choice>
<me:facs>&twodotPM;</me:facs>
<me:dipl>:</me:dipl>
</choice>
</pc>
<w>
<choice>
<me:facs>&mYGL;&oYG;&thGE;&aeMD;&rGE;</me:facs>
<me:dipl>moþær</me:dipl>
</choice>
</w>
<pc>
<choice>
<me:facs>&twodotPM;</me:facs>
<me:dipl>:</me:dipl>
</choice>
</pc>
<w>
<choice>
<me:facs>&tYG;&eMD;</me:facs>
<me:dipl>te</me:dipl>
</choice>
</w>
<pc>
<choice>
<me:facs>&twodotPM;</me:facs>
<me:dipl>:</me:dipl>
</choice>
</pc>
<w>
<choice>
<me:facs>&mYGL;&iGE;&kYG;</me:facs>
<me:dipl>mik</me:dipl>
</choice>
</w>
<pc>
<choice>
<me:facs>&twodotPM;</me:facs>
<me:dipl>:</me:dipl>
</choice>
</pc>
<w>
<choice>
<me:facs>&thGE;&aeMD;&tYG;</me:facs>
<me:dipl>þæt</me:dipl>
</choice>
</w>
<pc>
<choice>
<me:facs>&twodotPM;</me:facs>
<me:dipl>:</me:dipl>
</choice>
</pc>
<w>
<choice>
<me:facs>&iGE;&aYG;&kYG;</me:facs>
<me:dipl>iak</me:dipl>
</choice>
</w>
<pc>
<choice>
<me:facs>&twodotPM;</me:facs>
<me:dipl>:</me:dipl>
</choice>
</pc>
</p>
</div>In this example, {div} marks the start of the document,
more specifically the first chapter (which could be more precisely specified as
<div type="chapter" n="1"> in Menota
XML) starting in medias res on fol. 1r, and {/div} marks its end. The content is then placed between the two: {p} marks the beginning first paragraph within chapter 1 and
{/p} marks its end. The same would apply to the
following paragraphs of chapter 1.
The beginning of both div and p may
coincide with the beginning of the page and/or line. However, a document’s logical
structure (its division into chapters, paragraphs, section etc.) is independent of
its physical structure (its division into pages and lines). Therefore, the two are
encoded separately.
MBC div elements are translated in Menota XML as
unspecified <div> elements. After export,
it is recommended to specify these further with attribute like
@type
(
‘chapter’,
‘section’) or
@n (
‘1’,
‘2’,
‘3’).
4.2 Letters and entities
4.3 Usage of whitespace
4.4 Page and line breaks
by Robert K. Paulsen.
4.4.1 General
In Menota XML, page and line breaks in a manuscript are marked by so-called
milestone elements at the beginning of each page or line, e.g. <pb ed="ms" n="2r"/> for the beginning of
page “2r” and <lb ed="ms" n="3"/>
for the beginning of line “3” (cf. ch. 3.12 in the Menota handbook).
The MBC short-hand for this is the value of the @n attribute put between colons. Thus, the machine will interpret a number followed by “r” or “v” between colons as the beginning of a new page, and a number (without a following letter) between colons will be interpreted as the beginning of a new line:
| MenotaBlitz Code | Menota XML | Explanation |
|---|---|---|
:2r: | <pb ed="ms" n="2r"/> | for the beginning of page “2r” |
:3: | <lb ed="ms" n="3"/> | for the beginning of line “3” |
:10v: :1: |
<pb ed="ms" n="10v"/>
<lb ed="ms" n="1"/>
| for the beginning of page “10v”, which naturally starts with line “1” |
Any text of a manuscript can be located on a specific page and on a specific line. Therefore, MenotaBlitz will only parse text that is defined as such.
- Make sure that any transcribed text is preceded by an appropriate tag for its page and line!
- Make sure that any tag for page and line breaks are preceded and followed by whitespace (except for the cases discussed in 4.4.2 below).

Ill. XXX. Holm perg 34 4to, fol. 86r, lines 1-3.
Thus, the first three lines of fol. 86r in Holm perg 34 4to could be transcribed in like this in MBC:
{div}
{p} [...]
:86r:
:1: klofa ín [ln:S]tyri_m(&rsup;/aðr) skal leiðsogu_ma(n)n fa en aller tulk . [ln:A]llar
:2: lester skulu iam_sto&rrot;ar v(&er;/er)a at fullu fare nema sumum hasetom
:3: se skilld mi(n)ni . lest eða meiri . [ln:S]vo skal hvæ(&er;/r)r . hafa margra punda
[...]
{/p}
{/div}This translates into the following Menota XML (irrelevant sections cut out):
<div>
<p>
[...]
<pb ed="ms" n="86r"/>
<lb ed="ms" n="1"/>
<w>
<choice>
<me:facs>klo&fins;a</me:facs>
<me:dipl>klofa</me:dipl>
</choice>
</w>
[...]
<w>
<choice>
<me:facs><c type="littNot>A</c>llar</me:facs>
<me:dipl><c type="littNot>A</c>llar</me:dipl>
</choice>
</w>
<lb ed="ms" n="2"/>
<w>
<choice>
<me:facs>le&slong;ter</me:facs>
<me:dipl>lester</me:dipl>
</choice>
</w>
[...]
<w>
<choice>
<me:facs>ha&slong;etom</me:facs>
<me:dipl>hasetom</me:dipl>
</choice>
</w>
<lb ed="ms" n="3"/>
<w>
<choice>
<me:facs>&slong;e</me:facs>
<me:dipl>se</me:dipl>
</choice>
</w>
<w>
<choice>
<me:facs>&slong;kıll&drot;</me:facs>
<me:dipl>skilld</me:dipl>
</choice>
</w>
[...]4.4.2 Page and line break within words
Occasionally, page and especially line breaks occur within words, i.e. a word is not finished at the end of a line, but is continued on the next. Also in this case, MBC follows the principle that white space indicates word boundaries: You simply write the (page or) line break tag without any white space within the word.

Ill. XXX. AM 619 4to, fol. 4v, lines 8-9.
See the example on page 4v of AM 619 4to, where the word “huggir” starts at the end of line 8, but continues at the beginning of line 9. In MBC, you transcribe this as follows:
[...] þes er hug-:9:gir o&rrot;ð mín [...]This will translate into the desired Menota XML:
[...]
<w>
<choice>
<me:facs>þe&slong;</me:facs>
<me:dipl>þes</me:dipl>
</choice>
</w>
<w>
<choice>
<me:facs>er</me:facs>
<me:dipl>er</me:dipl>
</choice>
</w>
<w>
<choice>
<me:facs>hug<pc>-</pc><lb ed="ms" n="2"/>gır</me:facs>
<me:dipl>hug<pc>-</pc><lb ed="ms" n="2"/>gir</me:dipl>
</choice>
</w>
<w>
<choice>
<me:facs>o&rrot;ð</me:facs>
<me:dipl>orð</me:dipl>
</choice>
</w>
<w>
<choice>
<me:facs>mín</me:facs>
<me:dipl>mín</me:dipl>
</choice>
</w>Note that you must have checked the “pc” box for the grapheme “-” for this export to work properly (cf. 4.9).

Ill. XXX. Holm perg 34 4to, fol. 33r, lines 8-9.

Ill. XXX. Holm perg 34 4to, fol. 33v, lines 1-2.
The same logic applies if there is a page break within a word, as in Holm perg 34 4to [HP-34-4to-33r,27-28.png, HP-34-4to-33v,1-2], where the break from page 33r to 33v falls in middle of the word “heimanfylgia”. Use the usual MBC without any whitespace:
[...] en heí:33v::1:man_fylgia hennar [...]This will translate into the following Menota XML (cf. chapter 5.5 in the Menota handbook):
[...]
<w>
<choice>
<me:facs>en</me:facs>
<me:dipl>en</me:dipl>
</choice>
</w>
<w>
<choice>
<me:facs>heí<pb ed="ms" n="33v"/><lb ed="ms" n="1"/>man f&vinsdot;lgıa</me:facs>
<me:dipl>heí<pb ed="ms" n="33v"/><lb ed="ms" n="1"/>man fylgia</me:dipl>
</choice>
</w>
<w>
<choice>
<me:facs>hennar</me:facs>
<me:dipl>hennar</me:dipl>
</choice>
</w>
[...]4.4.3 Discontinuous text
Especially involving chapter headings, one will quite find a situation where the physical order of the text does not reflect its logical order directly (see ch. 16.3 in the Menota handbook):

Ill. XXX. AM 619 4to, fol. 47r, lines 14-17.
As exemplified on page 47r in AM 619 4to, the heading for a new chapter may be placed following the first few words of this beginning chapter, even though its logical position is obviously preceding these first few words. There are also other possibilities of chapter headings being placed in such a way that is not congruent with the text's logical order.
In Menota XML, this divergence is resolved by viewing the relevant lines as consisting of several sections which are number using a @rend attribute on the <lb/> elements indicating the line number, starting from the leftmost section. The transcription can then follow the text's logical order, indicating its physical order by the placement of such <lb/> elements.
In MBC this same sectioning is achieved by separating line number and section by a decimal point, so that the following would be a correct transcription of the example from the Menota handbook:
[...]
:15: (&et;/ok) rikir með fæðr (&et;/ok) hælgum anda æin guð utan enda ame&nscap; .
{/p}
{/div}
{div}
{head} :16.2: Jn+dedicatione templ()i . s(&er;/er)mo . {/head}
{p}
:16.1: [i:S]alomon k(onon)gr gerðe fyrst
:17: mysteri guði . (&et;/ok) bauð lyð sinu(m) at halda hotið þa er
[...]See sections 4.1, 4.3, 4.6 on how to encode document structure, white space, and abbreviations and respectively.
The same logic applies in cases where lines are not to be read in the physical top-to-bottom order, but in a different order: The transcription follows the logical order, but indicates the physical order by the placement of appropriate line break tags.

Ill. XXX. Klepp inscription, N 227.
The (drawing of the) runic inscription from the church in Klepp [Klepp.png], for instance, starts logically on its third line, then continues on the first and ends on the second. In MBC it would therefore correctly be encoded like this:
{div}
{p}
:1r:
:3: artiþ : er &threedotPM; ikib{eme{i}}arh[lig:ar] : kara:totr : þr{sic{u}cor{im}} :
no{eme{to}}m : æpter : krosmess{sic{t}cor{o}} : um . uar{sic{s}cor{e}t
:1: &crosPM; huær . sa : maþ{ill 1}r &threedotPM; runar : þez{eme{ar}} : sar : þa :
sy{ill 2} : bater : no{ill 1}er : fyrer : søl :
:2: heþnar : h{sic{a}cor{i}}albe : kuþ : þæim : er : suæ : kerer
{/p}
{/div}4.5 Special glyphs
4.6 Abbreviations
by Valerio Nazario Rossetti.
This section explains how to encode abbreviations in MenotaBlitz Code. Abbreviations with the stroke (or bar) abbreviation mark may be treated a bit differently than all other abbreviations, but in general the principle is always the same. This paragraph explains first how abbreviations are encoded in general and then focuses on those with the stroke.
4.6.1 General abbreviations
All abbreviations present in Old Norse manuscripts and fragments written in the
Latin Script may be encoded in the same way. I will give three examples with
different abbreviation marks (remember to follow the MUFI character
recommendation). As a general rule all the abbreviations are encoded
this way: (abbreviation-mark/expansion), i.e. in
parentheses the abbreviation mark and its expansion, separated by a forward
slash.
Here, abbreviation-mark represents the symbol (or the
XML-entity representing it) as it appears in the manuscript and how it will
appear in the facsimile version, while expansion is the
expanded reading of the abbreviation (which is how it will appear in a
diplomatic transcription, usually in italics). If a whole word is represented
by an abbreviation mark, there must be a space both preceding and following the
(abbreviation-mark/expansion) sequence.
If only part of a word is represented by an abbreviation mark, a space
following the (abbreviation-mark/expansion) sequence
must be put if the abbreviation occurs at the end of the word (while a space
preceding it must be in put if the abbreviation occurs at the beginning of the
word). If the abbreviation only represents the middle part of a word, there
must not be any space either preceding or following the (abbreviation-mark/expansion) sequence.

Ill. XXX.
The word here is konungr. The only letter written explicitly is the first, “k”. The symbol on top is the common zigzag abbreviation mark (most typically used to abbreviate “er”), which in this case stands for the rest of the word. As such, the word can be encoded this way:
k(&er;/onungr)This will translate into the following Menota XML:
<w>
<choice>
<me:facs>k<am>&er;</am></me:facs>
<me:dipl>k<ex>onungr</ex></me:facs>
</choice>
</w>

Ill. XXX.
This is the Tironian note with a stroke in the middle, represented by the
entity &etslash;. In Old Norse
manuscripts, it stands for the conjunction ok, which might be
written “ok”, “oc”, or “og” when not abbreviated in any given
manuscript. Assuming that our scribe writes the word “ok” when it is not
abbreviated, we want the the abbreviation to appear as such in the diplomatic
transcription and we can transcribe as follows:
(&etslash;/ok)This translates into the following Menota XML:
<w>
<choice>
<me:facs><am>&etslash;</am></me:facs>
<me:dipl><ex>ok</ex></me:dipl>
</choice>
</w>

Ill. XXX.
This is the ra abbreviation mark. It is usually expanded as “ra”, thus rendering the reading “fram” for our example, which can be encoded as follows:
f(&ra;/ra)mThis translates into the following Menota XML (given that one has defined f as representative of insular “ꝼ” in the
grapheme inventory, cf. 4.9):
<w>
<choice>
<me:facs>&fins;<am>&ra;</am>m</me:facs>
<me:dipl>f<ex>ra</ex>m</me:dipl>
</choice>
</w>4.6.2 The nasal stroke / bar abbreviation mark
The so-called nasal stroke, a bar over the preceding letter, encoded by the
entity &bar;, is by far the most
common abbreviation mark in Old Norse manuscript material. Therefore,
MenotaBlitz code offers a short-hand transcription alternative for this
particular symbol: Instead of (&bar;/expansion), one can use (expansion) to the same effect. The parser will interpret
both in exactly the same way.

Ill. XXX.
The word in this case is konungi, but the two letters in the middle, “nu”, are abbreviated by a bar. It can therefore be encoded as follows:
ko(nu)ngiwhich is a short-hand for the complete synonymous:
ko(&bar;/nu)ngiEither one translates into the following Menota XML (provided that one has
defined i as representative of dotless “ı”
in the grapheme inventory, cf. 4.9):
<w>
<choice>
<me:facs>ko<am>&bar;</am>ngi</me:facs>
<me:dipl>ko<ex>nu</ex>ngi</me:dipl>
</choice>
</w>

Ill. XXX.
The word in this case is the pronoun hann. It can be encoded as follows:
h(ann)This translates into the following Menota XML:
<w>
<choice>
<me:facs>h<am>&bar;</am></me:facs>
<me:dipl>h<ex>ann</ex></me:dipl>
</choice>
</w>4.6.3 Abbreviation marks without expansion
It can happen that an abbreviation mark is written by a scribe, but the editor does not deem it appropriate to expand it to anything. In this case, one simply does not write anything between the forward slash and the closing parenthesis, thus telling the parser that an abbreviation mark does not have an expansion.
Example.
This translates into the following Menota XML:
<w>
<choice>
<me:facs><am></am></me:facs>
<me:dipl></me:dipl>
</choice>
</w>4.6.4 Misplaced abbreviation marks
Occasionally, an abbreviation mark is not placed where it is expected, so that the <am> element of the facsimile transcription will have to appear in a different position in the word than the <ex> element of the diplomatic transcription. In such cases, one can use a combination of one abbreviation tag with an empty slot for the abbreviation mark and another abbreviation tag with an empty slot for the expansion.
See the following instance of the word honum:
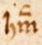
Ill. XXX.
The bar does not cross the “h”, but is above the “m”. This can be correctly transcribed as follows:
h(/onu)m()This translates into the following Menota XML:
<w>
<choice>
<me:facs>hm<am>&bar;</am></me:facs>
<me:dipl>h<ex>onu</ex>m</me:dipl>
</choice>
</w>Note that the sequence () translates into a nasal stroke
on the facsimile level without expansion!
This way, the facsimile edition will have the bar above the “m”, but the abbreviated letters in italics will appear in the right position following the “h”.
We can conclude:
- Diplomatic expansions that do not directly correspond to any abbreviation
marks are encoded as
(/expansion). - An abbreviation mark that does not (directly) correspond to any
expansion, is encoded as
(abbreviation-mark/)or as()if this abbreviation mark is a nasal stroke.
4.7 Interpretation and intervention
by Odd Einar Haugen and Robert K. Paulsen.
This section deals with a number of problems arising in the transcription of a text which for various reason cannot be rendered as a single, incontestable string of characters. It has been divided into three groups: firstly, rendering of readability, secondly rendering of actions by the scribe, such as adding or deleting text, and thirdly actions by the modern editor, such as supplying or suppressing text.
All these interventions are encoded using a similar syntax, being enclosed by a
pair of opening and closing tags. The opening tag always consists of an open curly
bracket: {, the tag name and another open curly bracket.
Two of these tags (add and del) may
have an optional modifier between the tag name and the second open curly bracket,
separated from the tag name by a space. The closing tag always consists of two
closed curly brackes: }}.
Two tags (gap and ill) may also be
empty, consisting only of the tag name enclosed in curly brackets.
These may have a modifier, as well, separated from the tag name by a space.
The sic/cor tag has a slightly different syntax.
Note that the use of space is crucial when transcribing in MBC. If a tag applies
to one or more characters within a word or numeral, no space should be used
following the opening tag or preceding the closing tag. In this example, the two
characters “ia” are encoded as unclear (by way of the ucl tag) and they are entered with no space on either side within the
curly brackets:
s{ucl{ia}}lfrPreceding the opening tag, a space must be used if (and only if) the tag applies to the first letter(s) of the word. Conversely, a space following the the closing tag must be used if (and only if) the tag applies to the last letter(s) of the word. In the example below, the last letter of “sinum” and the first two letters of “bonda” are marked as being restored readings:
m(&sem;/eð) sinu{res{m}} {res{b}}ondaIn this example, however, a whole word, “søkia”, has been encoded as unclear by the transcriber in the sequence “ok søkia eigi”. The unclear word should be entered with a space on either side of the opening and closing tags:
ok {ucl{ søkia }} eigi]]Note the use of space around the preceding and following word. The same applies to sequences of whole words that the transcriber wants to enclose in a tag:
bæðe runum {add rig{ (&et;/ok) latinustofu(m) }}Here, the two words “(ok) latinustofu(m)” are marked as being added in the right margin.
4.7.1 Unclearness
This chapter deals with text that is difficult or even impossible to read.
Unclearness is a common phenomenon in the transcription and encoding of
almost any kind of text. We recommend that if one or more characters are
unclear but can be read with some degree of certainty, they are placed
within the <unclear> element in Menota XML. For example, in the runic
inscription N 273, the second character in the word
“ᚱᛆᛁᛌᛐᛁ” cannot be read with full
certainty. This would be the transcription in MBC, using the ucl tag (for “unclear”):
r{ucl{a}}istiMenotaBlitz will tranlate this into the following Menota XML:
<w>
<choice>
<me:facs>&rGE;<unclear>&aYG;</unclear>&iGE;&sYGS;&tYG;&iGE;</me:facs>
<me:dipl>r<unclear>a</unclear>isti</me:dipl>
</choice>
</w>In MBC, if the character is downright illegible, the tag ill (for “illegible”) should be used, supplied with the number
of characters that seem to be missing. In the following example from N 540,
the final character is regarded as illegible, and this is stated by the
number 1:
furu{ill 1}This will produce the following Menota XML:
<w>
<choice>
<me:facs>&fGE;&uGE;&rGE;&uGE<unclear>◌</unclear></me:facs>
<me:dipl>furu<unclear>◌</unclear></me:dipl>
</choice>
</w>According to conventions, the dotted may be displayed by the stylesheet as a
such (Menota texts), an asterisk (Runic inscriptions), or possibly a number
of dots. The dotted circle used here should be regarded as an intermediate
representation in the Menota XML. Note that the number of dotted circle
corresponds to the value given in the MBC empty ill
tag.
If possible, the transcriber may want to try and restore the reading. In
MBC, this is done by inserting the restored reading in an ill tag. In this example, the encoder has decided that the final,
illegible character most likely is to be restored as an “m”:
furu{ill{m}}This will produce the following Menota XML:
<w>
<choice>
<me:facs>&fGE;&uGE;&rGE;&uGE<unclear>◌</unclear></me:facs>
<me:dipl>furu<unclear>m</unclear></me:dipl>
</choice>
</w>See the Menota Handbook ch. 8.4 for further details.
Lacunas are a particular challenge for the transcriber, since it in many
cases is difficult to estimate their size. In MBC, a lacuna should be
encoded with the empty gap tag whenever the
transcriber is unable to restore the text and only wants to state that there
is a lacuna in the text. In this example from the runic inscription N 63,
there is a gap with the width of two characters between “risþtu” and
“tir”:
risþtu {gap 2} tirNote that in MenotaBlitz Code the number refers to the presumed number of lost characters.
Thus it will produces the following In Menota XML, with the empty
<gap/> element, supplemented by a
@unit attribute with
the value
‘char’ (for “characters”) and a
@quantity
attribute with value corresponding to the modifier given in the MBC gap tag.
<w>
<choice>
<me:facs>&rGE;&iGE;&sYGS;&thGE;&tYG;&uGE;</me:facs>
<me:dipl>risþtu</me:dipl>
</choice>
</w>
<gap quantity="2" unit="char"/>
<w>
<choice>
<me:facs>&tYG;&iGE;&rGE;</me:facs>
<me:dipl>tir</me:dipl>
</choice>
</w>If the transcriber would like to restore the missing text, this should be
done using the res tag described in 4.7.3 below. In
this case, the <gap/> element will be generated automatically on the
Menota XML facsimile level.
In Menota XML, a restoration of will be expressed with a combination of the <gap/> element on the facsimile level and the <supplied> element on the diplomatic level. In this case, the <supplied> element will have the @reason attribute with the ‘restoration’ value, as explained in 4.7.3 below.
See the Menota Handbook ch. 8.2 for further details.
4.7.2 Interventions by the scribe
Interventions by the scribe will typically be the addition or the deletion of one or more characters or even whole words in the text.
Additions by the scribe are often found above the line, but also in the margin or below the line. There are sometimes signs that indicate the position of the addition. In some cases, it seems obvious that the addition was done by the scribe, while in other cases it may be a later scribe who was responsible for the addition. We recommend using the <add> element in all cases. One may, however, specify the position of the addition.
The table below lists all six possible modifiers of the MBC add tag and their correspondences in Menota XML:
| MenotaBlitz code | Menota XML |
|---|---|
{add{...}} | <add>...</add> |
{add sup{...}} | <add place="supralinear">...</add> |
{add inl{...}} | <add place="inline">...</add> |
{add lef{...}} | <add place="margin-left">...</add> |
{add rig{...}} | <add place="margin-right">...</add> |
{add top{...}} | <add place="margin-top">...</add> |
{add bot{...}} | <add place="margin-bottom">...</add> |
This is an example of an addition transcribed in MBC, using the add tag (for “addition”) with the modifier sup (for “supralinear”):
mis{add sup{k}}u(n)nThis translates into the following Menota XML:
<w>
<choice>
<me:facs>mi&slong;<add place="supralinear">k</add>u<am>&bar;</am>n</me:facs>
<me:dipl>mis<add place="supralinear">k</add>u<ex>n</ex>n</me:dipl>
</choice>
</w>See Menota Handbook ch. 9.2.1 for further details.
Deletions by the scribe are not uncommon in manuscripts and inscriptions. They are usually done by way of erasure and in manuscripts also by way of overstrike or subpunction. The manner of deletion may be expressed through one of three modifiers in MBC:
| MenotaBlitz code | Menota XML |
|---|---|
{del{...}} | <del>...</del> |
{del era{...}} | <del rend="erasure">...</del> |
{del ovs{...}} | <del rend="overstrike">...</del> |
{del sub{...}} | <del rend="subpunction">...</del> |
This is an example of how two deletions in a manuscript are transcribed in MBC, first of a whole word, “þer”, and then of a character within a word, “yður”, in which the “u” has been deleted so as to give the reading “yðr”:
viliu(m) {del era{ þer }} yð{del ovs{u}}rNote the use of white space around the complete word “þer”.
This translates into the following Menota XML:
<w>
<choice>
<me:facs>&vins;ılıu<am>&bar;</am></me:facs>
<me:dipl>viliu<ex>m</ex></me:dipl>
</choice>
</w>
<del rend="erasure">
<w>
<choice>
<me:facs>þer</me:facs>
<me:dipl>þer</me:dipl>
</choice>
</w>
</del>
<w>
<choice>
<me:facs>&ydot;ð<del rend="overstrike">u</del>r</me:facs>
<me:dipl>yð<del rend="overstrike">u</del>r</me:dipl>
</choice>
</w>See Menota Handbook ch. 9.2.2 for further details.
4.7.3 Interventions by the editor
In a multi-level transcription, the transcriber will as a rule render the
source text “as is” on the facsimile level. However, mistakes are bound to
occur in all but the shortest texts, and the transcriber might like to emend
the text, thus taking the step from being a mere transcriber to an
fully-fledged editor. In MBC, the following tags are at the editor’s disposal:
res, eme, dit, exc, and sic/cor.
They will be exemplified below and the corresponding Menota XML encoding
explained.
If there is a piece of text which is missing for some reason or another, the
editor may want to add it. This type of editorial addition will be regarded
as a restoration if the text has been left empty by intention, if it is
unclear or if it simply is illegible. Below is an example from the
manuscript AM 677 4to, f. 1v, l. 1, in which space has been allocated for an
initial, and the character “S” safely can be restored. In MenotaBlitz
Code this will be recorded by way of the res tag (for
“restoration”):
{res{[i:S]}}a einn madrIn Menota XML, this translates into a <supplied> element with a @reason attribute that has the value ‘restoration’ on the diplomatic level, while a <gap/> element will be produced on the facsimile level:
<w>
<choice>
<me:facs><gap/>a</me:facs>
<me:dipl><supplied reason="restoration"><c type="initial">S</c></supplied>a</me:dipl>
</choice>
</w>
<w>
<choice>
<me:facs>einn</me:facs>
<me:dipl>einn</me:dipl>
</choice>
</w>
<w>
<choice>
<me:facs>madr</me:facs>
<me:dipl>madr</me:dipl>
</choice>
</w>See the Menota Handbook ch. 9.3.1.1 for further details. When using the <supplied> element in Menota XML, it is recommended to specify the person (or edition) responsibile in a @resp attribute alongside the @reason attribute.
If there is a piece of text which the editor thinks is missing for lack of
syntactic, pragmatic or semantic congruity, even if no trace of it can be
found in the source, this text may be added as part of the editorial
process. This type of editorial intervention will be regarded as an
emendation. While a restoration may be characterised as the editor’s
hypothesis of what originally was written in a certain location of the
primary source, an emendation is rather the editor’s suggestion of what
should have been written. Below is an example from the manuscript AM 619
4to, f. 14r, l. 26-30, in which “ok mannlegra” has been added (in fact
based on the Latin source). An MBC transcription uses the eme tag (for “emendation”):
guðlegra luta {eme{ ok mannlegra }}Note the space on either side of the two words. As explained in the introduction, space must be used when complete words are enclosed in a tag.
This produces Menota XML with a <supplied> that has the attribute @reason with the value ‘emendation’ on the diplomatic level, while the facsimile level will be left empty:
<w>
<choice>
<me:facs>guðlegra</me:facs>
<me:dipl>guðlegra</me:dipl>
</choice>
</w>
<w>
<choice>
<me:facs>luta</me:facs>
<me:dipl>luta</me:dipl>
</choice>
</w>
<supplied reason="emendation">
<w>
<me:facs/>
<me:dipl>ok</me:dipl>
</w>
<w>
<me:facs/>
<me:dipl>mannlegra</me:dipl>
</w>
</supplied>See the Menota Handbook ch. 9.3.1.2 for further details. When using the <supplied> element in Menota XML, it is recommended to specify the person (or edition) responsibile in a @resp attribute alongside the @reason attribute.
There are several types of superfluous text, but by far the most common one
is the dittography, either of a part of a word or of a whole word (or even
several words). One example among many is found in AM 243 b a fol, f. 2v,
col. B, l. 18-19, where “sialfr” has been written twice – first at the
end of l. 18 and next at the beginning of l. 19. This would be the
transcription in MenotaBlitz Code, using the dit tag
(for “dittography”):
sialfr :19: {dit{ sialfr }}Note that since the dittography is a whole word, it has to be transcribed with a space on either side within the curly brackets. Also note the encoding of line 19.
This translates into Menota XML with a <surplus> element with the attribute @reason that has the value ‘dittography’:
<w>
<choice>
<me:facs>&slong;ıal&fins;r</me:facs>
<me:dipl>sialfr</me:dipl>
</choice>
</w>
<lb ed="ms" n="19"/>
<surplus reason="dittography">
<w>
<choice>
<me:facs>&slong;ıal&fins;r</me:facs>
<me:dipl>sialfr</me:dipl>
</choice>
</w>
</surplus>See the Menota Handbook ch. 9.3.2 for further details.
Sometimes, there will be a piece of text which the editor believes should be
suppressed due to its lack of meaning or relevance. One should always be
careful with respect to suppression, for even if the editor does not find a
the text meaningful, other scholars may be able to give it an acceptable
interpretation. In MBC one should use the exc tag
(for “excess”), such as in this example where there are two
conjunctions, “ok” and “eða”, and one of them, perhaps the first
one, should be suppressed:
sia {exc{ ok }} eða høyraNote that since the suppressed piece of text is a whole word, it has to be transcribed with a space on either side.
This translates into Menota XML with a <surplus> with the attribute @reason that has the value ‘excess’:
<w>
<choice>
<me:facs>&slong;ıa</me:facs>
<me:dipl>sia</me:dipl>
</choice>
</w>
<surplus reason="excess">
<w>
<choice>
<me:facs>ok</me:facs>
<me:dipl>ok</me:dipl>
</choice>
</w>
</surplus>
<w>
<choice>
<me:facs>eða</me:facs>
<me:dipl>eða</me:dipl>
</choice>
</w>
<w>
<choice>
<me:facs>h&ocurl;&ydot;ra</me:facs>
<me:dipl>høyra</me:dipl>
</choice>
</w>See the Menota Handbook ch. 9.3.2 for further details.
In many cases, the editor will be faced with a piece of text which seems
incorrect according to grammatical rules, or with respect to pragmatic or
semantic contents. It is recommended that the text in the source is
transcribed so that both the original reading and its correction is
recorded. In MBC, this is achieved by the sic/cor
(for “sic” and “correction” respectively) which has a unique
syntax: it does not only have an opening tag {sic{
and a closing tag }} (as always), but also a
middle-tag }cor{ which separates the original from
the emended reading.
Here, the editor believes that “søkia” should be replaced with “sia”:
sem þetta bref {sic{ søkia }cor{ sia }}This will produce the following Menota XML, where the <sic> and <corr>> elements will be used in a similar way, and since they present alternate ways of reading the text, they will be enclosed in a <choice> element:
<w>
<choice>
<me:facs>&slong;em</me:facs>
<me:dipl>sem</me:dipl>
</choice>
</w>
<w>
<choice>
<me:facs>þetta</me:facs>
<me:dipl>þetta</me:dipl>
</choice>
</w>
<w>
<choice>
<me:facs>bre&fins;</me:facs>
<me:dipl>bref</me:facs>
</choice>
</w>
<choice>
<sic>
<w>
<choice>
<me:facs>&slong;&ocurl;kıa</me:facs>
<me:dipl>søkia</me:dipl>
</choice>
</w>
</sic>
<corr>
<w>
<choice>
<me:facs/>
<me:dipl>sia</me:dipl>
</choice>
</w>
</corr>
</choice>See the Menota Handbook ch. 9.3.3 for further details. When using the <corr> element, it is recommended to specify the person (or edition) responsibile for the correction in a @resp attribute.
4.8 Numerals
by Patrick Farrugia.
MenotaBlitz offers a streamlined method of encoding (Roman) numerals as outlined in section 5.7 of version 3.0 of the Menota handbook.
In MenotaBlitz Code, one can label a Roman numeral by simply entering a number
sign, “#”, directly preceding the number
that appears in the text.

Ill. XXX. Roman numeral “.x.” in AM 764 4to 20r.7.
Let’s look at this example from AM 764 4to, a passage which chronicles the successions of Roman emperors, and thus contains plenty (!) of numerals. This numeral could be transcribed directly in MenotaBlitz code as:
[...] li:7:cíní&jacute; #.x. a(&rsup;/r) . Galeríu&sscap; [...]Note that the MenotaBlitz software will recognize a number simply based on the # sign, and the Menota XML generated through the export
function will reflect this.
[...]
<num>
<choice>
<me:facs><pc>.</pc>x<pc>.</pc></me:facs>
<me:dipl><pc>.</pc>x<pc>.</pc></me:dipl>
</choice>
</num>
[...]One must have defined the dot “.” as a punctuation mark in the grapheme inventory in order for the above XML code to be produced, cf. section 4.9.
4.9 Grapheme inventory
by Tonje Waldersnes and Robert K. Paulsen.
4.9.1 General graphemes
As discussed in section 4.2, one has to use a unique letter or XML-like entity
in MenotaBlitz Code for each grapheme (or graph-type) one wishes to distinguish
in the resulting transcription(s). As mentioned, these need not be the exact
correspondences in terms of Unicode points, but must be unique for each symbol
one wants to distinguish: A scribe may for instance use round “ꝺ”,
but never straight “d”. In such a case, it is recommended to use “d” in order to transcribe this letter in MBC.
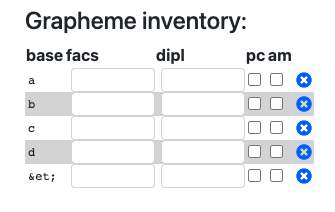
Ill. XXX. A small grapheme inventory after initial compilation.
Upon pressing the “Compile” button, the program will read through the text entered in the “Editor” field and list all used letters and entities alphabetically next to it in a grapheme table. Before one can view the transcription on the facsimile or diplomatic level (in the “Facs” and “Dipl” tabs respectively), one has to define each grapheme's facsimile and diplomatic rendering.
As mentioned, a grapheme table will be produced based on the symbols used in
the transcription. These symbols appear in the table in the column labeled
“base”. In the input fields next to this, one enters the facsimile and
diplomatic renderings of each grapheme. Drawing on the earlier example, here
you would enter “&drot;” in the
“facs” column and “d” in the “dipl”
column.
Note that the restrictions on possible entries in these input fields are
somewhat different from those applying to MBC: Here you may use
any special character you like (e.g. “ǿ”, “ß”, “ÿ”), while XML entities are restricted to those defined in the emroon entity list,
which is largely identical to the Menota entity list
and follows the MUFI
character recommendation.

Ill. XXX. A small grapheme inventory after definition and second compilation.
Upon pressing the “Compile” button again, the program will find the actual symbols associated with the entities in a suitable font and display them to the left of the input field in the grapheme table. Thus, you can check at any time which letter or enity you have defined as representing which glyph in the manuscript, while maintaining an easy to type and read transcription style in the editor window.
Once all graphemes have been sufficiently defined, you can also read your transcription on both the facsimile and the diplomatic focal levels in the appropriate tabs on the website.
If you are not happy with a grapheme, or believe it is of no use, you can click on the “x” button in the appropriate row of the grapheme table in order to remove it. The grapheme will reappear upon pressing the “Compile” button if it is still contained in the transcription.
4.9.2 Abbreviation marks
Abbreviation marks are different from other graphemes in that they do not need to be represented on the diplomatic level: Rather than being transcribed, abbreviations are expanded in a diplomatic transcription, i.e. they are represented by a sequence of letters that the editor believes the glyphs to abbreviate.
As such, it is not appropriate for anything to be defined as the “dipl” reading of an abbreviation symbol in the grapheme table. Simply check of the box labeled “am” and click “Compile” for the appropriate “dipl” input field to disappear.
4.9.3 Punctuation marks
You can define a symbol as a punctuation mark by checking of the box labeled
“pc” in the grapheme table. This typically applies to simple symbols
like “.” or “:”, but also applies to more complicated ones like
“”, being represented by “&punctelev;”.
If a symbol is defined as a punctuation mark, the machine will generate a <pc> element around any instance of this grapheme occurring, both inside and outside of words and numerals (but not within abbreviations).