Ch. 8. Fragmentation and uncertainty
Version 3.0 (12 December 2019)
by Odd Einar Haugen and Nina Stensaker
8.1 Introduction
Some Medieval Nordic manuscripts have been preserved in their entirety and they are, for the most part, easily readable and encodeable. The recommendations in ch. 3 cover most aspects of the document structure in these manuscripts. However, surprisingly many manuscripts and the majority of the earliest manuscripts have been preserved in a less than complete state. This chapter will discuss how to deal with various degrees of fragmentation, ranging from minor holes in a leaf to once large codices now preserved only in tiny fragments. It also deals with uncertainty, whether it is a passage of one or more characters that can not be read with full certainty or a passage which is downright illegible. For this reason the elements <gap/>, <space/> and <unclear> will be essential to the chapter. They can be used on all three levels of encoding, i.e. the facsimile, diplomatic and normalised levels (cf. ch. 4 above).
In some of these cases, the encoder might want to supply the missing or unclear text, either from other manuscripts or by conjecture, using the <supplied> element. This type of editorial intervention will be discussed in ch. 9.3.1 below.
In some manuscripts, there are holes or imperfections which must have been original, such as in fig. 8.1. Here, the text simply continues on the other side of the hole, so from a textual point of view, it is not necessary to encode the presence of the hole. The same applies to leaves which are not fully sized, e.g. by being shorter by width or height than other leaves in the manuscript.

Ill. 8.1. An original hole in the manuscript. The Old Norwegian Homily Book. AM 619 4to, f. 35v, l. 15–22.
In the present ch. 8 and the ensuing ch. 9 we will frequently refer to and give examples of single-level and multi-level transcriptions. Please refer to ch. 4.5 and ch. 4.6 for these important concepts.
8.2 Lacunas
The size of a lacuna varies considerably and may be nothing more than a small hole in a leaf of the manuscript, while in other cases, the lacuna may consist of a whole leaf, a whole quire or even several quires of the once complete manuscript.
8.2.1. Encoding of lacunas
Whenever the manuscript contains a lacuna we suggest using the element <gap/>, whatever the extent of the lacuna. We use the term lacuna in a strict sense, referring to any part of a manuscript which is physically missing. This element has several attributes, specifying size and reason for the lacuna:
| Elements & attributes | Obl/Opt | Contents |
|---|---|---|
| <gap/> | Is an element without extention in the encoded manuscript text. It indicates a point where material has been omitted in a transcription because it is physically missing in the manuscript. Attributes include: | |
| @unit | Obligatory | Names the unit used for describing the extent of the gap. Values will typically be ‘char’ (character), ‘word’, ‘line’ or ‘leaf’, or even ‘indeterminate’. |
| @quantity | Optional | Indicates approximately how much text has been omitted from the transcription. Values can be given as e.g. number of characters, words, lines or leaves in the manuscript, i.e. ‘1’, ‘2’, ‘3’, etc. Note that only numbers are accepted as values; the category is described in the @unit attribute.If the extent of the gap is described as ‘indeterminate’ in the @unit attribute, it does not make sense to try and specify a quantity. |
| @reason | Optional | Gives the reason for omission. Sample values include: ‘damaged’, ‘cut’, ‘missing’. |
| @agent | Optional | In the case of text omitted because of damage, categorises the cause of the damage, if it can be identified. Values can be ‘rubbing’, ‘smoke’, ‘fungus’ or the like. Intended removal of text, i.e. by erasure, should be encoded using the <del> element discussed in ch. 9.2.2 below. |
In fig. 8.2 there are several examples of damaged text. Some characters have evidently been lost due to damage from the “S” initial on the other side of the leaf. In the fourth line from the bottom, we can read “Fegiarn maðr er lícr hælviti þvi er aldrigin ...lisc”. Probably three characters are now lost in the last word. With some knowledge of Old Norse, it is reasonable to suggest that they are “fyl”, so that the whole word would be “fyllisc”.

Ill. 8.2. Damage to the parchment caused by acidity. The Old Norwegian Homily Book. AM 619 4to, f. 9v, l. 23–30.
On the facsimile level, we encode the gaps as such and do not offer any hypothesis on the contents of the lost text, as shown in this single-level transcription:
. . .
<w><me:facs>Fegiarn</me:facs></w>
<w><me:facs><am>ᛉ</am></me:facs></w>
<w><me:facs>er</me:facs></w>
<w><me:facs>lícr</me:facs></w>
<w><me:facs>hæl&vins;iti</me:facs></w>
<w><me:facs>þ&vins;i</me:facs></w>
<w><me:facs>er</me:facs></w>
<w><me:facs>aldrigin</me:facs></w>
<w><me:facs><gap reason="damage" quantity="3" unit="char"/>lisc</me:facs></w>
<pc><me:facs>.</me:facs></pc>
. . .If the encoder would like to restore the lost text, this can be done by the <supplied> element discussed in ch. 9.3.1 below.
On the normalised level, the text should be supplied, if possible, while it is a matter of editorial policy whether it should be supplied or not on the diplomatic level. If there are rather few examples of damaged text, such as in the Old Norwegian Homily Book most encoders would supply damaged text on the diplomatic level, especially if it is a single-level edition. This has been done in the edition of the text in the Menota archive. If the source text is an extensively damaged fragment, on the other hand, the encoder may choose to retain the encoding with its uncertainties on the diplomatic level, and leave any restoration to the normalised level. Some of the damaged fragments of Konungs skuggsjá has been encoded in this way in the Menota archive, e.g. NRA 58C.
This is what a single-level encoding on the diplomatic level would look like if the encoder wanted to use the <supplied> element. Here, Gustav Indrebø in his 1931 edition of the text is credited with the restoration:
. . .
<w><me:dipl>Fegiarn</me:dipl></w>
<w><me:dipl><ex>maðr</ex></me:dipl></w>
<w><me:dipl>er</me:dipl></w>
<w><me:dipl>lícr</me:dipl></w>
<w><me:dipl>hælviti</me:dipl></w>
<w><me:dipl>þvi</me:dipl></w>
<w><me:dipl>er</me:dipl></w>
<w><me:dipl>aldrigin</me:dipl></w>
<w><me:dipl><supplied reason="restoration" resp="GI1931">fyl</supplied>lisc</me:dipl></w>
<pc><me:dipl>.</me:dipl></pc>
. . .As stated above, however, one may also keep the <gap/> encoding on the diplomatic level. The encoding would then be like this:
. . .
<w><me:dipl>Fegiarn</me:dipl></w>
<w><me:dipl><ex>maðr</ex></me:dipl></w>
<w><me:dipl>er</me:dipl></w>
<w><me:dipl>lícr</me:dipl></w>
<w><me:dipl>hælviti</me:dipl></w>
<w><me:dipl>þvi</me:dipl></w>
<w><me:dipl>er</me:dipl></w>
<w><me:dipl>aldrigin</me:dipl></w>
<w><me:dipl><gap reason="damage" quantity="3" unit="char"/>lisc</me:dipl></w>
<pc><me:dipl>.</me:dipl></pc>
. . .In ch. 8.5 below, examples of larger lacunas are given.
8.2.2. Display of lacunas
Stylesheets will vary with respect to the display of the <gap/> element. They are also likely to take into consideration the length of the presumed lost text. This can be anything from a single character to several leaves of a once complete codex.
In the stylesheet for the Menota archive, each presumed lost character is displayed by a dotted circle, in Unicode known as 25CC DOTTED CIRCLE. If the lacuna has a length of more than one line (as specified in the attribute), each line will be displayed with a series of three dotted circles + one line missing + three dotted circles. Longer lacunas (more than one leaf) will be explained in a note, and the same applies to lacunas of indeterminate length.
A suitable stylesheet will be able to pick values from the attributes of the <gap/> element and display them accordingly. Note that in XML encoding, it is no use hitting the space bar more than once in order to produce a larger space than the ordinary one, so the extent of the lacuna must be specified by the attributes if it is going to be displayed at all.
| Element | Smaller lacunas | Larger lacunas |
|---|---|---|
| <gap/> | By a number of dotted circles, ◌◌◌ (25CC, entity &circledot;), corresponding to the estimated number of characters in the lacuna. If the lacuna is longer than a line, each line will be displayed with a series of three dotted circles + one line missing + three dotted circles |
By a note stating the approximate length of the lacuna and possibly some comment on its contents |
Other stylesheets may prefer to render missing characters with a small zero sign, such as F1BD SMALL BASE LINE ZERO SIGN, entity &smallzero; in the Private Use Area of the MUFI character recommendation. They might also add that if the number of presumed missing characters is too high, e.g. more than 10, it will be stated in numbers, such as “ca. 15”.
8.3 Empty space
Manuscripts often have empty spaces, typically left for initials but also in other contexts, for example for words to be added at a later stage in the writing process.
8.3.1. Encoding of empty space
The <space/> element is used to represent deliberate omissions by the scribe, e.g. spaces left for decorated initials or whole words. This element has several attributes, specifying the size and dimension of the space:
| Elements & attributes | Obl/Opt | Contents |
|---|---|---|
| <space/> | Is an element without extention in the encoded manuscript text. It indicates a point in a transcription of a manuscript where the manuscript has a deliberate omission and has left an open space for later usage, either by the scribe or another scribe. Attributes include: | |
| @quantity | Obligatory | Indicates approximately the size of the space. Values can be given as e.g. number of characters, words, lines or leaves in the manuscript, i.e. ‘1’, ‘2’, ‘3’, etc. Note that only numbers are accepted as values; the category is described in the @unit attribute. |
| @unit | Obligatory | Names the unit used for describing the extent of the space. Values will typically be ‘char’ (characters) and ‘word’. |
| @dim | Optional | Indicates the dimension of the space, i.e. whether it is ‘horizontal’ or ‘vertical’. For irregular shapes in two dimensions, the value for this attribute should reflect the more important of the two dimensions. In conventional left-right scripts, a space with both vertical and horizontal components should be classified as vertical. |
In fig. 8.3, the scribe of Landslǫg Magnúss Hákonarsonar (Magnus Lagabøtes landslov) has left space for the amount of silver to be paid, so that it could be supplied at a later stage. Perhaps his exemplars were conflicting here and he wanted to add the specific amount after having compared sources. From other manuscripts of this law text we know that the amount was half a mark (mǫrk f.).

Ill. 8.3. Place left open towards the end of the last but one line in the image. Landslǫg Magnúss Hákonarsonar. AM 309 fol, f. 42v, l. 10–19.
On the facsimile level, the space left for the amount of silver in fig. 8.3 can be encoded as follows in a single-level transcription:
<pb ed="ms" n="42v"/>
. . .
<lb ed="ms" n="18"/>
. . .
<w><me:facs>en</me:facs></w>
<w><me:facs>nu</me:facs></w>
<w><me:facs>e<am>&er;</am></me:facs></w>
<w><me:facs>skílt</me:facs></w>
<pc><me:facs>.</me:facs></pc>
<w><me:facs>giallde</me:facs></w>
<pc><me:facs>.</me:facs></pc>
<space quantity="3" unit="char"/>
<w><me:facs>S<am>&er;</am></me:facs></w>
<pc><me:facs>.</me:facs></pc>
<w><me:facs>Sv</me:facs></w>
<w><me:facs>e<am>&er;</am></me:facs></w>
<w><me:facs>on<am>&bar;</am>ur</me:facs></w>
<lb ed="ms" n="19"/>
<w><me:facs>s&ocurl;k</me:facs></w>
. . .
If the encoder would like to restore the text intended for the space, this can be done by the <supplied> element discussed in ch. 9.3.1 below. The editorial considerations in a multi-level transcription are the same as for the treatment of lacunas above, i.e. that a space should be encoded as a space and nothing more on the facsimile level, the intended text should, if possible, be supplied at the normalised level, while the policy on the diplomatic level depends on the manuscript and its degree of preservation and completeness.
A single-level transcription on the diplomatic level would look like this if the encoder decided to use the <supplied> element:
<pb ed="ms" n="42v"/>
. . .
<lb ed="ms" n="18/>"
. . .
<w><me:dipl>en</me:dipl></w>
<w><me:dipl>nu</me:dipl></w>
<w><me:dipl>e<ex>r</ex></me:dipl></w>
<w><me:dipl>skílt</me:dipl></w>
<pc><me:dipl>.</me:dipl></pc>
<w><me:dipl>giallde</me:dipl></w>
<pc><me:dipl>.</me:dipl></pc>
<supplied reason="restoration" resp="encoder">
<w><me:dipl>halfa</me:dipl></w>
<w><me:dipl>mork</me:dipl></w>
</supplied>
<w><me:dipl>S<ex>ilfrs</ex></me:dipl></w>
<pc><me:dipl>.</me:dipl></pc>
<w><me:dipl>Sv</me:dipl></w>
<w><me:dipl>e<ex>r</ex></me:dipl></w>
<w><me:dipl>on<ex>n</ex>ur</me:dipl></w>
<lb ed="ms" n="19"/>
<w><me:dipl>s&ocurl;k</me:dipl></w>
. . .
Since the scribe left room for approximately three characters, he would obviously not have written “halfa mork” in full, but perhaps something like “.ɟ. ᴍ.”. However, when supplying text, we recommend to make it as readable as possible. See ch. 9.3.4 below for a brief discussion of the orthography of supplied (and corrected) text.
In another example, fig. 8.4, there is an empty space for an initial. This is often seen in manuscripts, since initials typically were drawn after the main text was written. Here, the space is evidently intended for the single character “S” in the word sá ‘this’.

Ill. 8.4. Missing initial. Gregory’s Homilies and Dialogues. AM 677 4to, f. 1v, l. 1–3.
The space has a size of approximately four characters horizontally and two lines vertically. According to the TEI P5 Guidelines, a space with both vertical and horizontal components should be classified as vertical (cf. the description of the @dim attribute). So, in this case, we might measure the space along the vertical dimension and the natural measure is the number of lines. This would be a single-level transcription on the facsimile level:
. . .
<w><me:facs><space quantity="2" unit="line" dim="vertical"/>a</me:facs></w>
<w><me:facs>eiɴ</me:facs></w>
<w><me:facs><am>ᛉ</am></me:facs></w>
. . .However, since we recommend to focus on the text rather than on the page and column layout, we suggest that it may be sufficient to indicate the number of missing characters. In this case it is 1, the initial, so the transcription could be simplified to the following:
. . .
<w><me:facs><space quantity="1" unit="char"/>a</me:facs></w>
<w><me:facs>eiɴ</me:facs></w>
<w><me:facs><am>ᛉ</am></me:facs></w>
. . .If the transcriber would like to restore the text intended for the space, this can be done by the <supplied> element as stated above. A single-level transcription on the diplomatic level would look like this:
. . .
<w><me:dipl><supplied reason="restoration" resp="encoder">S</supplied>a</me:dipl></w>
<w><me:dipl>eiɴ</me:dipl></w>
<w><me:dipl><ex>madr</ex></me:dipl></w>
. . .
This restoration is so obvious that the encoder might not want to hunt it down in earlier editions of the text, but only give his or her initials in the @resp attribute. We will return to this example in ch. 9.3.1.1 below.
For more details on the encoding of initials and other graphical elements, see ch. 7.3 above.
8.3.2. Display of empty space
An empty space may be anything from a single character, typically set aside for an initial, to larger areas, even whole leaves. The display needs to adapt to the variability in size. In the stylesheet for the Menota archive, smaller areas will be displayed by spaces, while larger areas have to be indicated by a note inserted by the transcriber.
| Element | Smaller areas | Larger areas |
|---|---|---|
| <space/> | By a number of spaces, , corresponding to the estimated number of characters
in the empty area, or in a number of line beginnings in otherwise empty lines,
<lb/>, corresponding to the estimated number of lines in the empty area |
By a note inserted by the transcriber stating the approximate length of the empty area |
Other stylesheets may choose to display empty space differently, including having no display at all.
8.4 Unclear text
Many manuscripts contain text that is difficult or even impossible to read. It can be a single character, a word, a phrase or even longer passages. We recommend using the <unclear> element in such cases whatever the degree of unclearness. The reason for the unclearness may be described by the attribute @reason and values such as ‘faded’, ‘smudged’ and ‘erased’. In cases where the physical reason for the unclearness can be identifed, this may be set out in the @agent attribute.
When a character can be read with some degree of certainty, we recommend that this character is entered in the <unclear> element, so that it can be displayed as such. If a character is completley unreadable, it should still be entered in the <unclear> element, but using a specific character such as a dotted circle or a small zero (explained below).
One might be tempted to try and indicate the degree of unclearness by a suitable attribute, for example by a percentage, but we believe that this is a rather arbitrary measure and difficult to estimate. In other words, characters which cannot be read with full certainty, simply are <unclear>. A corresponding facsimile of the text should be available and will help the users to estimate the degree of unclearness.
8.4.1 Encoding of unclear text
| Elements & attributes | Obl/Opt | Contents |
|---|---|---|
| <unclear> | Contains a character, word, phrase or passage which cannot be transcribed with certainty. Attributes include: | |
| @reason | Optional | Indicates why the material is hard to transcribe. Sample values include: ‘faded’, ‘smudged’, ‘erased’. |
| @agent | Optional | Where the difficulty in transcription arises from an identifiable cause, this can be described. Sample values include: ‘rubbing’, ‘mildew’, ‘smoke’. |

Ill. 8.5. A word which is difficult to read. Blasíuss saga. AM 655 IX 4to, f. 2r, l. 1–5.
In fig. 8.5, the 6th word in the 3rd line is difficult to read. It may be the verb veita ‘give’, but this reading is far from certain, so the transcriber should state that this is in fact an unclear passage. Whenever the uncertain passage is part of a word, the <unclear> element will be placed within the <w> element, but when the uncertain passage contains one or more words, the <unclear> element will be located outside.
A single-level transcription on the diplomatic level of this line is shown below. Note that we here, the <unclear> element is placed outside the <w> element:
<pb ed="ms" n="2r"/>
. . .
<lb ed="ms" n="3"/>
<w><me:dipl>postola</me:dipl></w>
<w><me:dipl>sinum</me:dipl></w>
<pc><me:dipl>.</me:dipl></pc>
<w><me:dipl>Ðat</me:dipl></w>
<w><me:dipl>ma</me:dipl></w>
<w><me:dipl>han</me:dipl></w>
<unclear reason="smudged"><w><me:dipl>veita</me:dipl></w></unclear>
<w><me:dipl>mer</me:dipl></w>
. . .
The encoding above is on the diplomatic level. We recommend that the <unclear> element should be used in the same way also in single-level encodings on the facsimile and normalised levels.
Note that the fissure in lines 4–5 must be original, so that e.g. the word “fiolda” in line 5 is written with “fiol” on the left-hand side and “da” on the right-hand side of the fissure. This is another example of original damage to the parchment discussed in ch. 8.1 above.

Ill. 8.6. An illegible word. Niðrstigningar saga. AM 645 4to, f. 51v, l. 32–35.
In fig. 8.6, the first character in the second line is so smudged that it has become illegible. We recommend that illegible characters are encoded by a standard sign such as 25CC DOTTED CIRCLE (cf. ch. 8.2.2 above). This would be a single-level transcription on the diplomatic level:
<pb ed="ms" n="51v"/>
. . .
<w><me:dipl>at</me:dipl></w>
<w><me:dipl>fagna</me:dipl></w>
<w><me:dipl>miog</me:dipl></w>
<lb ed="ms" n="32"/>
<unclear reason="smudged"><w><me:dipl>◌</me:dipl></w></unclear>
<w><me:dipl>m<ex>æ</ex>la</me:dipl></w>
<w><me:dipl>s<ex>va</ex></me:dipl></w>
<pc><me:dipl>.</me:dipl></pc>
<w><me:dipl>lios</me:dipl></w>
<w><me:dipl>þ<ex>ett</ex>a</me:dipl></w>
<w><me:dipl>mon</me:dipl></w>
<w><me:dipl>scina</me:dipl></w>
. . .
From the context, one can assume that the illegible character is the Tironean nota for “ok”, and that it thus is a whole word which is illegible. For this reason, the dotted circle has been placed inside a <w> element.
In this example, we can be fairly certain that the unclear passage is a single word, so the <unclear> element is located within a single <w> element. In other cases, we can see that many words are missing but we may not have access to other manuscripts of the text. If it thus is impossible to estimate the number of words, we suggest leaving out the <w> element within the <unclear> element, only specifying by the number of dotted circles how many characters seem to be missing. Assuming that all the words in the first line of fig. 8.6 were illegible apart from “at fagna miog” and that the number of missing characters was estimated to be 28, the encoding would be as follows:
<pb ed="ms" n="51v"/>
. . .
<lb ed="ms" n="32"/>
<unclear reason="smudged">◌◌◌◌◌◌◌◌◌◌◌◌◌◌◌◌◌◌◌◌◌◌◌◌◌◌◌◌</unclear>
<w><me:dipl>at</me:dipl></w>
<w><me:dipl>fagna</me:dipl></w>
<w><me:dipl>miog</me:dipl></w>
<lb ed="ms" n="32"/>
<unclear reason="smudged"><w><me:dipl>◌</me:dipl></w></unclear>
<w><me:dipl>m<ex>æ</ex>la</me:dipl></w>
<w><me:dipl>s<ex>va</ex></me:dipl></w>
<pc><me:dipl>.</me:dipl></pc>
<w><me:dipl>lios</me:dipl></w>
<w><me:dipl>þ<ex>ett</ex>a</me:dipl></w>
<w><me:dipl>mon</me:dipl></w>
<w><me:dipl>scina</me:dipl></w>
. . .
Since the transcriber can insert a suitable text in the <unclear> element, it is possible to do so in a more concise and rather self-explanatory manner, e.g.
<pb ed="ms" n="51v"/>
. . .
<lb ed="ms" n="32"/>
<unclear reason="smudged">◌◌◌ ca. 28 ◌◌◌</unclear>
<w><me:dipl>at</me:dipl></w>
<w><me:dipl>fagna</me:dipl></w>
<w><me:dipl>miog</me:dipl></w>
. . .
If the encoder would like to restore illegible characters, this can be done by the <supplied> element discussed in ch. 9.3.1 below. The editorial considerations are similar to the treatment of lacunas above, i.e. that illegible characters should be encoded with a sign like 25CC DOTTED CIRCLE on the facsimile level, the characters should, if possible, be supplied at the normalised level, while the policy on the diplomatic level depends on the manuscript and its degree of preservation and completeness.
A single-level transcription on the diplomatic level would look like this if the enocder decided to use the <supplied> element:
<pb ed="ms" n="51v"/>
. . .
<w><me:dipl>at</me:dipl></w>
<w><me:dipl>fagna</me:dipl></w>
<w><me:dipl>miog</me:dipl></w>
<lb ed="ms" n="32"/>
<w><me:dipl><supplied reason="restoration" resp="OEH">ok</supplied></me:dipl></w>
<w><me:dipl>m<ex>æ</ex>la</me:dipl></w>
<w><me:dipl>s<ex>va</ex></me:dipl></w>
<pc><me:dipl>.</me:dipl></pc>
<w><me:dipl>lios</me:dipl></w>
<w><me:dipl>þ<ex>ett</ex>a</me:dipl></w>
<w><me:dipl>mon</me:dipl></w>
<w><me:dipl>scina</me:dipl></w>
8.4.2 Display of unclear text
In the stylesheet for the Menota archive, a light grey colour is used for characters in the <unclear> element. This colour is also used for characters that are illegible and encoded by the dotted circle, 25CC.
| Element | Display in a single-level transcription | Display in a multi-level transcription |
|---|---|---|
| <unclear> | Characters are rendered in grey. | Characters are rendered in grey on the <me:facs> and <me:dipl> levels, but in ordinary, non-coloured characters on the <me:norm> level. |
Stylesheets differ somewhat with respect to the display of unclear passages. Some stylesheets, for example, would prefer to render unclear characters with subpunction, such as in many printed editions. As for illegible characters, small zeros are mostly used in printed editions.
8.5 Fragments
A fragment can be defined as anything less than 50 % of a once complete manuscript, but it is commonly used for much shorter remains of a manuscript, perhaps only a few leaves, a single leaf, or even a small bit of a leaf. Fragments can be quite challenging with respect to the encoding of their document structure, even if the text itself is perfectly readable. Below, we will be looking at four examples, focusing on how to deal with their document structure and how to refer to the missing text which surrounds them.
8.5.1 Several leaves
NRA 7 is the largest fragment of Landslǫg Magnúss Hákonarsonar (Magnus Lagabøtes landslov), containing seven leaves from various parts of the law. One of the leaves is in fact preserved as three individual pieces. The encoding of this leaf will be discussed in ch. 8.5.4 below.
The sequence of the leaves making up NRA 7 can be established by full certainty, since this text is preserved in around 40 well-preserved manuscripts. We recommend that the leaves should be foliated in the sequence they have in the otherwise established text, from folio 1 to folio 7. Of these leaves, folios 3–4 and 6–7 are consecutive, but between the remaining leaves, there are a number of lost leaves.
When the loss of leaves is so high as in this case, it may be difficult to specify the amount of missing leaves between each preserved one. It might, however, be possible to establish the sequence using a series of <gap/> elements, showing where there is continuity and where there is not:
<gap unit="leaf"/>
<note type="codicology">Many leaves from the beginning of the once complete manuscript</note>
<pb ed="ms" n="1r"/>
. . .
<pb ed="ms" n="1v"/>
. . .
<gap unit="leaf"/>
<note type="codicology">Several leaves</note>
<pb ed="ms" n="2r"/>
. . .
<pb ed="ms" n="2v"/>
. . .
<gap unit="leaf"/>
<note type="codicology">Several leaves</note>
<pb ed="ms" n="3r"/>
. . .
<pb ed="ms" n="3v"/>
. . .
<pb ed="ms" n="4r"/>
. . .
<pb ed="ms" n="4v"/>
. . .
<gap unit="leaf"/>
<note type="codicology">Several leaves</note>
<pb ed="ms" n="5r"/>
. . .
<pb ed="ms" n="5v"/>
. . .
<gap unit="leaf"/>
<note type="codicology">Several leaves</note>
<pb ed="ms" n="6r"/>
. . .
<pb ed="ms" n="6v"/>
. . .
<pb ed="ms" n="7r"/>
. . .
<pb ed="ms" n="7v"/>
. . .
<gap unit="leaf"/>
<note type="codicology">Many leaves until the end of the once complete manuscript</note>
As for the use of the <note> element here, see ch. 9.4 below.
From this encoding, we understand that the beginning and the end of the once complete manuscript is missing, and that there are gaps in between all leaves apart from between folios 3 and 4, and between folios 6 and 7. Since the attribute @quantity requires an exact number, and it in many cases is impossible to give an estimate of this, we suggest using the <note> element to specify this, perhaps adding some comment on which parts might have been part of the gap (if the text is known from other manuscripts).
8.5.2 A pair of leaves
Quires were made up of pairs of leaves, bifolia, and it is not uncommon that one or more bifolia are missing from the quire, often the inner or outer bifolium. Unless the bifolium belongs to the inner part of a quire, the text will not be consecutive.
The type of fragmentation can be illustrated with quires number IX–X of AM 619 4to. According to the standard foliation of the manuscript, there is an outer bifolium missing between the present folios 62 and 63, and between folios 68 and 69, and an inner bifolium missing between folios 70 and 71, as shown in ill. 8.7. There will thus be three lacunas in the text: one lacuna of one leaf (two pages) between folios 62 and 63, one lacuna of two leaves (four pages) between folios 68 and 69, and one lacuna of two leaves (four pages) between folios 70 and 71. Finally, there will be a lacuna after folio 72. The extent of this lacuna depends on the state of the next quire and is thus not shown in fig. 8.7.
Note that the foliation of the manuscript is consecutive, so there is nothing in these numbers that indicate that there is a gap between folios 62 and 63, between 68 and 69, and between 70 and 71.
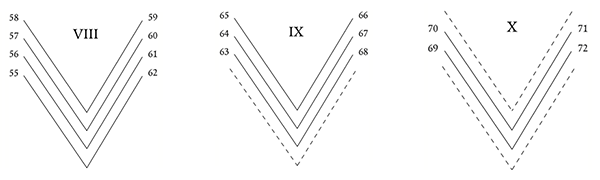
Ill. 8.7. Quires VIII, IX and X of The Old Norwegian Homily Book, AM 619 4to. Missing leaves are indicated by dotted lines.
The missing leaves are not immediately visible in the codex, which has been bound at a later stage. However looking at the bottom of folio 62 verso, it is stated by a younger hand that a leaf is missing. By reading folios 62 verso and 63 recto, it is also clear that a piece of text is missing, but not immediately how much.

Ill. 8.8. A missing leaf (part of a bifolium). AM 619 4to, f. 62–63. Note the addition in a younger hand at the bottom of f. 62v, stating “deest .i. folium” (one leaf is missing). This is actually the hand of Árni Magnússon (identified by Beeke Stegmann).
As recommended above, the missing text should be indicated by the <gap/> element, so that the first lacuna, between folios 62 and 63, will be encoded like this in a singe-level transcription on the diplomatic level:
<pb ed="ms" n="62v"/>
. . .
<w><me:dipl>bøt</me:dipl></w>
<w><me:dipl>með</me:dipl></w>
<w><me:dipl>scripta</me:dipl></w>
<gap quantity="1" unit="leaf"/>
<pb ed="ms" n="63r"/>
<lb ed="ms" n="1"/>
<w><me:dipl>er</me:dipl></w>
<w><me:dipl>hinn</me:dipl></w>
<w><me:dipl>helgi</me:dipl></w>
. . .Since the extent of the gap is specified by the attributes to the <gap/> element, no codicological note is called for. However, we recommend that the transcriber adds an explanatory note, so that users will have some guidance as to what is missing and to what extent it can be supplied from e.g. other manuscripts. This note should be concise and using non-technical language, for example:
<pb ed="ms" n="62v"/>
. . .
<w><me:dipl>bøt</me:dipl></w>
<w><me:dipl>með</me:dipl></w>
<w><me:dipl>scripta</me:dipl></w>
<gap quantity="1" unit="leaf"/>
<note type="explanation">A leaf is missing between folios 62v and 63r.
The text can be supplied from another manuscript, Upps DG 8 II,
f. 106.18–108.20</note>
<pb ed="ms" n="63r"/>
<lb ed="ms" n="1"/>
<w><me:dipl>er</me:dipl></w>
<w><me:dipl>hinn</me:dipl></w>
<w><me:dipl>helgi</me:dipl></w>
. . .In the Menota archive, explanatory notes will be displayed at relevant places in the edited text. The use of these notes is discussed in ch. 9.4 below.
8.5.3 A single leaf
There are several early Norwegian fragments of Konungs skuggsjá (Speculum regale). One of these is NKS 235 g 4to, a single fragment in two columns, each of 27 lines, as illustrated in fig. 8.9.

Ill. 8.9. A fragment consisting of a single leaf. Konungs skuggsjá. NKS 235 g 4to, f. 1.
The document structure of NKS 235 g 4to is simple. Since it is the only leaf preserved from presumably a once complete codex, there is no alternative but to call it folio 1. On either side of this leaf, there will be a considerable lacuna, the first from the beginning of the codex, the second until the end (unless the manuscript never was completed):
<gap unit="leaf"/>
<note type="codicology">Many leaves from the beginning of the once complete manuscript</note>
<pb ed="ms" n="1r"/>
<cb ed="ms" n="A"/>
<lb ed="ms" n="1"/>
. . .
<cb ed="ms" n="B"/>
<lb ed="ms" n="1"/>
. . .
<lb ed="ms" n="27"/>
<pb ed="ms" n="1v"/>
<cb ed="ms" n="A"/>
<lb ed="ms" n="1"/>
. . .
<cb ed="ms" n="B"/>
<lb ed="ms" n="1"/>
. . .
<lb ed="ms" n="27"/>
<gap unit="leaf"/>
<note type="codicology">Many leaves until the end of the once complete manuscript</note>
Also in this case, the encoder may consider an explanatory note, e.g. stating where in the text of Konungs skuggsjá the fragment is located.
8.5.4 One or more pieces of a leaf
The tiniest fragments are small strips or cuttings of leaves. In archives and libraries, each individual fragment is typically given a separate signature. When it is possible to piece several fragments together as parts of a single leaf we recommend that they are encoded as parts of this leaf, and not as individual fragments. Ill. 8.10 shows three pieces brought together as parts of a single leaf.

Ill. 8.10. Three pieces belonging to a single leaf. Landslǫg Magnúss Hákonarsonar. NRA 7, f. 2v.
The three pieces belonging to a single leaf in fig. 8.10 can be shown to be part of the second of the seven leaves. They should therefore be encoded as folios 2r and 2v, and they should be given line numbers to the extent that this can be ascertained. Since several other leaves of this once complete manuscript have been preserved, one can be fairly certain about the number of lines on a leaf, as well as the position of the pieces in each of the two columns.
Taking the single piece from column A on folio 2v as an example, the document structure would thus be:
<pb ed="ms" n="2v"/>
<cb ed="ms" n="A"/>
<lb ed="ms" n="11"/>NU ma maðr bøta
<lb ed="ms" n="12"/>rað sunar sínns. oc læiða
. . .
<lb ed="ms" n="18"/>tækr ætt leíðíngr þo eígí merí arf
<lb ed="ms" n="19"/>en sa stoð till er arfi iattaði. Sa skal
The whole leaf 2v would then be encoded with the <gap/> element like this:
<pb ed="ms" n="2v"/>
<cb ed="ms" n="A"/>
<gap quantity="10" unit="line"/>
<lb ed="ms" n="11"/>NU ma maðr bøta
. . .
<lb ed="ms" n="19"/>en sa stoð till er arfi iattaði. Sa skal
<gap quantity="8" unit="line"/>
<cb ed="ms" n="B1"/>
<lb ed="ms" n="1"/>Sua skall kono ættleiða sem karll-
. . .
<lb ed="ms" n="8"/>þat fe allt hafa sem hann er till
<cb ed="ms" n="B2"/>
<lb ed="ms" n="9"/>læídðr meðan þæír lifa er ættleíðu
. . .
<lb ed="ms" n="19"/>fyrír í þæírí villu. at hann
<gap quantity="8" unit="line"/>
As suggested in ch. 8.5.2 and ch. 8.5.3 above, explanatory notes might be added about the missing text on this leaf.