Appendix A: Characters
Version 3.0 (12 December 2019)
by Odd Einar Haugen
A.1 Characters in Medieval Nordic sources
The Unicode Standard now offers a large selection of characters in the Latin alphabet for the encoding of Medieval Nordic texts. For texts encoded on a diplomatic level, hardly any characters will be missing in the Standard, and even for texts encoded on a facsimile level, the great majority of characters, perhaps all, will be available. (See ch. 4 for an explanation of levels of transcription.)
The fact that a character has received a codepoint in the Unicode Standard does not mean that it will be part of standard fonts. This is a decision to be made by the font producers. For the time being, many of the more unusual Nordic characters are only part of a few specialised fonts. See app. B for links to available fonts, some of which can be downloaded for free.
Also texts written in runes, in whole or in parts, can be encoded according to the Unicode Standard, but the number of Runic characters in the Standard is limited, and there are also rather few fonts which contain all the Runic characters listed in the Standard. This is the present Unicode selection of runes:
The Wikipedia article on runes in Unicode can be recommended:
A.2 Synchronisation with MUFI
As of v. 2.0 of the Menota handbook, the selection and encoding of characters have been synchronised with the MUFI character recommendation. In v. 4.0 of this recommendation, there are more than 1,500 characters in the Latin alphabet of potential use for the encoding of Medieval Nordic primary sources:
- The MUFI character recommendation v. 4.0 (published 22 December 2015)
The MUFI character recommendation lists Unicode codepoints and entity names for all characters in the file. Exactly the same entity names have been used in the Menota list of entities, cf. app. D.1.1 (2).
The MUFI character recommendation and the Menota entity list was compatible with the Unicode Standard v. 8.0, published 17 June 2015. The Unicode Standard has now moved on to v. 12.0, but to the best of our knowledge, there are no additions to the Standard with respect to Medieval Nordic characters.
The MUFI website has been redesigned after Tarrin Wills took over as chair of MUFI in 2016. It is now possible to search for characters directly from the website: http://mufi.info.
A.3 Characters outside the Menota entity list
If a character is not listed in the Menota entity list, it can still be encoded using a suitable character entity. Note, however, that a display of such characters require a proprietary font. These entities must be declared at the beginning of the XML file, at the end of the !ENTITY declaration. A list of entities for runic characters with corresponding codepoints in the Unicode Standard may look like this:
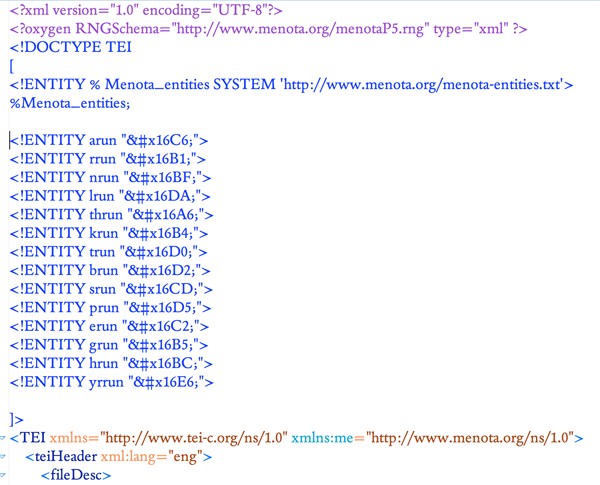
Ill. A.1 . Declaration of entities outside the Menota list
Note that the closing of the !ENTITY declaration should be at the end of the list of additional entities, i.e. before the final ]> characters.