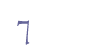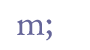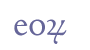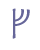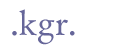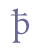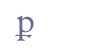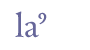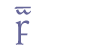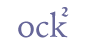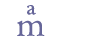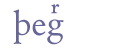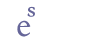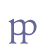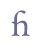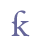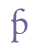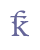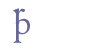| Menota main page List of contents |
 |
|
|
Chapter 6. Abbreviations: typology and encoding6.1 Introduction Version 2.0 (16 May 2008). Links updated 12 July 2016. 6.1 IntroductionAbbreviations are a common feature of medieval manuscripts. In the medieval Nordic tradition, abbreviations were used most frequently in Norwegian and Icelandic manuscripts, and particularly in the latter. In some Icelandic manuscripts as many as a third of the words may be abbreviated, some of them with several abbreviation marks. The system of abbreviations was inherited from English and Continental practice, but the adoption of this system also meant that the usage of some abbreviation marks was extended and it led to the development of some new types. The encoding of abbreviations is discussed in the TEI P5 Guidelines in ch. 11, particularly ch. 11.3.2. As of this version, four elements are defined:
TEI P5 recommends that abbreviations spanning a whole word is encoded with the <abbr> element, while the actual abbreviation can be encoded with the <am> element, e.g. <abbr>xpc</abbr> han<am>&bar;</am> In the first line of this example, the sequence “xpc” is an abbreviation for “christus”. This is a nomen sacrum using originally Greek characters and should therefore be interpreted as a special abbreviation character (brevigraph). The abbreviation in the second line is by far the most common one in Medieval Nordic sources. Here, a part of the word, an “n”, has been abbreviated by way of putting a horizontal bar above the preceding character. Even if the element <abbr> can be used for the first type and <am> for the second, we suggest that the element <am> should be used in both cases. An abbreviation of the whole word can simply be seen as a borderline case of an abbreviations of a word part. A similar distinction is drawn in TEI P5 between the <expan> element, which contains an expansion of a whole word, and the <ex> element, containing the expanded part of the word, e.g. <expan>christus</expan> han<ex>n</ex> In the first line of this example, the abbreviation “xpc” has been expanded as “christus”, meaning that there are no overlapping characters between the abbreviation (the brevigraph) and the expansion. In the second line, the horizontal bar has been expanded as “n”. We recommend using the <ex> element in both cases, for similar reasons as for the use of the <am> element. In a multi-level transcription, the <am> element typically belongs to the facs level, while the <ex> element belongs to the dipl level. The norm level usually have none, e.g. The <am> element may have a @me:type attribute specifying what kind of abbreviation it is. The same applies to the <ex> element. We have not given examples of these attributes in the present chapter, but users may refer to the typology in ch. 6.2 below if they would like to make a more detailed encoding.
In this chapter, we shall give a typology of abbreviation and then exemplify a number of cases. 6.2 TypologyAbbreviations are usually divided into four categories (see e.g. Hreinn Benediktsson 1965, p. 85 and, for a more detailed classification, Kristian Kålund 1907, pp. viii-x): (1) Suspensions. The first part of the word, often the initial letter only, is written out, followed by a dot or similar mark. The plural may be represented by a doubling of the initial letter, e.g. “ss.” = synir (sons). (2) Contractions. Some letters are left out, but the initial and final letters are written out, often one or more of the intermediate as well. The abbreviation is often indicated with a horizontal bar above the word. (3) Interlinear marks. The interlinear abbreviation is usually a vowel representing either “r” or “v” + the vowel itself or a consonant representing “a” + the consonant itself. (4) Special signs (brevigraphs). These signs are usually placed on the base line and are thus akin to ordinary letters. The Tironian notae belong to this category. The typology in ch. 6.3 below takes as its point of departure the location of the abbreviations. The main distinction is drawn between abbreviation signs placed on the base line and those placed above (or through or below) a base line character. We suggest that letter-sized characters on the base line are referred to as signs, while combining abbreviation marks (above, through or below another character) are referred to as marks. For the sake of simplicity, however, we shall refer to both categories as marks in this chapter. 6.2.1 GlyphsGlyphs are displayed in the Andron font by Andreas Stötzner (Leipzig). The regular version of this font can be downloaded from the MUFI font page. Since abbreviation marks typically appear as parts of words and are frequently associated with a base line character we have chosen to illustrate each mark within the context of a whole word. 6.2.2 Entity namesAll abbreviations are referred to with entity names, with the exception of full stop, “.”, and colon, “:”. Entity names are placed within the delimiters “&” and “;”, and we have tried to give as short and mnemonic names as possible. As a rule, we have based the entity name on the typical expansion of the abbreviation. Thus, the cross mark which is an abbreviation for “kross” is given the entity name “✗”. We aim at synchronizing our use of entities with those recommended by ISO, but since there presently are no abbreviation entities in ISO, we are left to our own devices in this chapter. 6.2.3 Unicode valuesUnicode 5.0 has only defined a handful of abbreviation characters and only a few of interest for our use. The great majority of abbreviation characters must therefore be defined as code values in the Private Use Area. The only exceptions are the full stop, colon and semicolon, which are part of the range Basic Latin in Unicode, and the Tironian sign for et, in the range General Punctuation. For a complete list of suggested Unicode values, see Appendix A below. 6.2.4 Descriptive namesAs is the case with ordinary characters (cf. ch. 5) we adhere to the naming scheme in Unicode. Since Unicode 5.0 only defines one abbreviation mark in the Latin alphabet, the TIRONIAN SIGN ET in the range General Punctuation, and only one in each of the Armenian, Syriac, Devanagari, Thai and Khmer alphabets, we do not have completley clear examples of descriptive names. We suggest ABBREVIATION SIGN “000” as a general name for abbreviations occupying a separate position on the base line, and COMBINING ABBREVIATION MARK “000” for those typically placed above, through or below a base line character. 6.3 Abbreviation marks on the base lineAbbreviation marks on the base line behave as any other character. The typology of these abbreviation marks is discussed and exemplified below. 6.3.1 The “et” markThe Tironian nota resembling the number “7” (or the character “z” with or without a crossbar) is often used for the conjunction “ok” / “oc” (in Latin “et”). We recommend using the entity name “&et;”, reflecting the Latin origin of the abbreviation. In Unicode 5.0 this character is located at 204A in the range General Punctuation.
There are two major variants of this sign. If the transcriber wishes to make a distinction between these, we suggest using “&et;” for the sign without a crossbar and “&etslash;” for the sign with a crossbar. The code point for the latter is F158. 6.3.2 The “ed” markThe semicolon was used for “e” + dental consonant, often in the preposition “með”. We recommend “&sem;” as entity name. In Unicode 5.0 the semicolon is located at 003B in the range Basic Latin. When the semicolon is used as a punctuation mark, it should be transcribed as such, i.e. simply as “;”. When it is used as an abbreviation mark we recommend that it is transcribed with an entity, “&sem;”. Note that there is another form of this abbreviation mark, looking like the number “3”. This is included in the MUFI character recommendation at code point F155 and can be encoded with the entity “&etfin;”.
6.3.3 The “con” markA sign resembling a backwards “c” was often used for “con” in Latin and “kon” in Nordic words. This “con” mark is similar to 0254 LATIN SMALL LETTER OPEN O in the range IPA Extensions of Unicode 5.0 and may be identified with this character.
See the MUFI character recommendation for other variants of the “con” mark (descending and with a dot). 6.3.4 The “rum” markThe sequence “rum” was often abbreviated with a character resembling a small version of the number 4 (in fact, it is the round “r” with a stroke across its tail). We recommend the entity name “&rum;” and a separate code point in the Private Use Area.
6.3.5 The cross markThe word “kross” was sometimes abbreviated with the cross symbol, which we suggest calling “✗”. This “kross” mark can be identified with 271D LATIN CROSS in the range Dingbats of Unicode 5.0.
6.3.6 The “m” runeThe runic character for “m” was sometimes used for the word “maðr” (including case forms with the stem “mann-”). We recommend the entity name “&mMedrun;”, as introduced in ch. 5.3.7. Unicode 5.0 has defined a selection of 81 runes from the Older and Younger Futhark in the Runic range. This range includes the “m” rune.
The runic character may appear with interlinear marks (“a”, “i”, “e”, “n”, “z”) for various inflected forms of the word “maðr”, e.g. “manna”, “manni”/“manne”, “mann”, “mannz”. The encoding of this type is discussed in ch. 6.4.7 below. 6.3.7 The “f” runeThe runic character for “f” was sometimes used for the word “fé”. In analogy with the use of the “m” rune, we suggest the entity name “&fMedrun;”. The “f” rune is included in the Runic range of Unicode 5.0.
6.3.8 Dot (full stop)Dots were often used as abbreviation marks, typically for suspensions, e.g. “s.” for “sonr” (or “segja”, “svara”). They may sometimes appear on both sides of the abbreviated word, “.s.”. We recommend that the dot is transcribed in the same manner as a full stop, i.e. with the “.” mark in Basic Latin. Thus, no entity name is called for.
If the transcriber wishes to distinguish between the dot used as an abbreviation mark and the dot used as a punctuation mark, we suggest that the entity name “.” could be used in the former case and “.” in the latter. However, we believe that there will arise a number of cases where it is difficult to decide whether the dot in the manuscript is a mark of abbreviation, punctuation or both, e.g. when a suspended word is the last word in a sentence. We therefore believe it is better to accept that the full stop is an ambivalent mark, as is also (although to a much lesser extent) the case with the colon and the runic characters “f” and “m”. When the encoder believes that the full stop is an abbreviation mark that should be indicated simply by using the <am> element, as shown here. 6.3.9 ColonThe colon is sometimes, though not often, used as a mark of suspension, in the same manner as the dot (full stop). In analogy with the encoding of dots we suggest transcribing the colon simply as a colon, i.e. without using an entity.
6.3.10 Small capitalsIn Old Icelandic, small capitals were used to denote geminated (long) consonants or they were simply used ornamentally (especially in Old Norwegian). In ch. 5.3.3 above we recommended that they were encoded as entities in both cases. The use of small capitals can be seen as a form of abbreviation, but there will be a number of cases where the usage is open to interpretation. We recommend that the transcriber copies the text as it is, transcribing a small capital as a small capital irrespective of whether it is being used to denote gemination or as an ornament. Thus, exactly the same entities will be used here as introduced in ch. 5.3.3.
For the encoding of small capitals with dot above, please see ch. 6.4.8 below. 6.4 Combining abbreviation marksThe majority of abbreviation marks are placed above, through or below a base line character. It could be argued that they really refer to the whole word, but from an analytical point of view we recommend that they are encoded immediately after the base line character to which they seem most closely associated. Cf. the rules in ch. 2.2.1. It is sometimes difficult to decide whether a sign is placed on the base line or above another base line character. For example, the “us” mark (cf. ch. 6.4.3 below) may sometimes occupy a position of its own, although slightly raised above the base line. The classification in this chapter is based on what we believe are the prototypical positions of the abbreviation marks. 6.4.1 Horizontal barThe horizontal bar is from a historical point of view the earliest form of an abbreviation mark and it is also the most ambiguous type. It is commonly used for “m” or “n” and is often referred to as a “nasal stroke”, but it is also used in a number of other contexts, as a mark of suspension or contraction. We recommend using the same entity name in all instances, “&bar;”. The unmarked position of the bar is above the immediately preceding character. This horizontal bar is partially similar to 0304 COMBINING MACRON and 0305 COMBINING OVERLINE in the range Combining Diacritical Marks of Unicode 5.0, and may be identified with the latter.
In the last example, the bar crosses the ascender of the character “þ”. In our view, this is only a coincidence, since the bar in all cases is placed above the x height of the base line character. If there is a character with an ascender, the bar will simply cross this stroke. The unmarked position of the bar is above the base line character, and this is therefore part of the definition of the entity “&bar;”. In some cases the bar may be placed below the base line character. Here, we suggest the entity name “&barbl;” (for “bar below”). The horizontal bar below is partially similar to 0331 COMBINING MACRON BELOW or 0332 COMBINING LOW LINE in the range Combining Diacritical Marks of Unicode 5.0, and may be identified with the latter.
It is possible to identify various shapes of the horizontal bar. In general we recommend that the transcriber should not make more distinctions than strictly necessary. If the transcriber for some reason would like to create a typology of bar forms, we suggest that this is done by numbering, “&bar-1;”, “&bar-2;”, “&bar-3;”, etc. The meaning of each entity must be explained in the header of the transcription and specified in the entity list (cf. Appendix D below) 6.4.2 FlourishThe flourish may be described as a horizontal bar with a return. It appears in the abbreviation of the Latin word “pro” in contradistinction to “per”, which typically is abbreviated with a simple horizontal bar. We suggest using the entity name “&combflour;” and recommend that it is given a separate code point in the Private Use Area.
6.4.3 The “us” markOriginally a Tironian nota, a mark resembling a small version of the number “9” is often used for “us”. It is usually placed in a raised position, though not always clearly above the preceding character. Since the typical position of this mark is above the base line, we regard it as a combining mark and suggest the entity name “&us;” and recommend that it is given a separate code point in the Private Use Area.
6.4.4 The “er” markA mark resembling a zigzag was frequently used as abbreviation of a front vowel (including diphtongs) + “r”, e.g. “ir”, “er”, “eir”, “ær”. The earliest form resembles a horizontal stroke with a descender to the left and an ascender to the right. It later acquired a zigzag-like form and even later resembles the letter “u” turned upside-down. This abbreviation mark has now become part of the Unicode Standard (based on its usage in Lithuanian) in the range Combining diacritical marks.
6.4.5 The “ra” markOriginally an open form of the character “a”, this mark was used as an abbreviation for “ra” or “va”. One variant resembles the Greek omega-sign and another variant the omega-sign with a horizontal bar above. We suggest using the entity name “&ra;” for the first type and “&rabar;” for the second. We recommend that both marks are given separate code points in the Private Use Area.
6.4.6 The “ur” markThe syllable “ur” (sometimes “yr”) can be abbreviated by a mark resembling a small version of the number 2. A second form of this mark resemble a tilde, and a third form a horizontal version of the number 8 (equal to the lemniskate symbol), cf. Hreinn Benediktsson 1965, p. 91. Due to the considerable variation in form we suggest that it might be useful to distinguish between three main forms, using the entity “&urrot;” for the first type, “&ur;” for the second and “&urlemn;” for the third. The code points are respectively F153, F1C3 and F1C2 (all in the Private Use Area).
6.4.7 Interlinear charactersInterlinear characters are a common type of abbreviation. An interlinear vowel typically represents a consonant (often “r”) + the vowel itself, while an interlinear consonant typically represents a vowel (often “a”) + the consonant itself. We suggest that interlinear abbreviation marks are named by the character itself + “sup” (for “superscript”), e.g. “&asup;” (interlinear “a”), “&osup;” (interlinear “o”), “&rscapsup;” (interlinear small capital “r”), etc. Unicode 5.0 includes a selection of 13 superscript characters, namely “a”, “e”, “i”, “o”, “u”, “c”, “d”, “h”, “m”, “r”, “t”, “v”, “x”. They are located at the end of the range Combining diacritical marks, 0363-036F. We suggest that these characters are used to display interlinear characters and that characters outside this selection are given separate code points in the Private Use Area.
The runic character “m”, which itself can be used as an abbreviation (cf. ch. 6.3.6 above), can appear with an interlinear abbreviation mark. The encoding follows the pattern above.
Since the first entity, “&mrun;”, is defined as a base line character and the second, “&asup;”, as an interlinear mark placed above the immediately preceding base line character, there will be no doubt as to the positioning. 6.4.8 Superscript dotsSuperscript dots are sometimes used to denote length. It is a moot question whether this is a type of abbreviation, but in any case the transcriber should use an entity for the encoding. We recommend that superscript dots are transcribed in analogy with other combining abbreviation marks and suggest using the entity name “&combdot;” (for “combining dot above”). Unicode 5.0 has a combining dot above in the range Combining diacritical marks.
Sometimes the dot is used above small capitals. Since small capitals themselves are a way of representing gemination, the dot above is redundant. The encoding will simply be the same as above. Cf. ch. 6.3.10 above.
6.5 Special cases6.5.1 Nomina sacraIn some cases the whole word must be analysed as an abbreviation. This applies to the traditional nomina sacra, i.e. abbreviations for sacred words such as “iesus” and “christus”. These contain characters which originally were Greek but might be taken for Latin characters. For example, the “p” in “xpm” is originally a Greek “rho” (“r”). We believe these abbreviations should be encoded as a sequence of the individual base line characters and one or more combining bars above. In the examples below, the originally Greek base line characters have been identified with the similar-looking Latin characters. Greek characters might also have been used in the encoding (such as “&igr;” for GREEK SMALL LETTER IOTA, etc.).
Note that the combining bar above has been encoded more than once in these examples. That ensures an appropriate display of the manuscript text, since the bar will be shown as extending over the whole word. However, it may be argued that there is only a single bar in each example, and that this bar simply happens to extend over more than one character. This problem is discussed more fully in ch. 6.5.5 below. 6.5.2 Interlinear characters in other contextsInterlinear (superscript) characters are used in various ways, not always as abbreviations. According to de Leeuw van Weenen 2000: 36-43 there are four types: (a) as abbreviation This type is discussed in ch. 6.4.7 above. Here, we recommend the usage of entities such as “&asup;”. (b) as addition When interlinear characters are used for adding characters which were left out by the scribe we recommend that this is encoded by use of the element <add> and the attribute @place="supralinear" (cf. ch. 7.2). There is no need for an entity of the type “&asup;” since the location of the character is indicated by the element.
(c) as complementation of Roman numbers Inflected forms of Roman numbers are sometimes specified by interlinear characters. In these cases, the interlinear characters are not placed above any base line character but merely raised above the base line. We suggest using the element <seg> and the attribute @type="superscript".
(d) as space savers Especially at the end of a line one or more characters may be placed above the last word to save place and complete the line. We suggest the same encoding as in (c) above.
6.5.3 Missing abbreviation markFrom time to time one can find examples of a word that obviously is abbreviated but where there is no trace of the abbreviation mark. There is then no alternative but transcribing the text as it reads in the manuscript.
6.5.4 Nesting (stacking) of abbreviation marksThere are a few examples of base line characters which are abbreviated with an abbreviation mark which is itself abbreviated. An example is the base line character “m” with an interlinear “o” which in turn has a horizontal bar. According to rule 7 in ch. 2.2.1 above this abbreviation should be encoded as the sequence “m” + “&osup;” + “&bar;”.
Since “&osup;” is defined as a combining character, it follows that it is placed above the immediately preceding character, in this case “m”, and since “&bar;” is also defined as a combining character, it follows that it is placed above “&osup;”. There is therefore no doubt as to the positioning of each part. 6.5.5 Extension of abbreviation marksAs a rule, combining abbreviation marks are associated with a single base line character. Thus, the sequence “m&osup;” means that the interlinear character “o” is seen as being placed above “m” and not above any other character. However, some abbreviation marks extend over more than one character. For example, the word “k(ir)kia” may be abbreviated with a horizontal bar crossing both the first and the second “k”. We believe it is sufficient to associate the abbreviation mark with only one of these characters, preferably the first.
It is possible to encode this word so that the bar is associated with both characters. This is in a sense closer to the manuscript form, but it means that a single abbreviation mark may appear as two distinct marks (unless it is somehow stated that the two marks belong together). Thus, this is a more complex and possibly misleading solution.
On the other hand, it should be noted that this a case where 0305 COMBINING OVERLINE is appropriate, since it connects to left and right. Cf. the reference in ch. 6.4.1 above. 6.5.6 Sporadic ligatures with abbreviation marksIn ch. 5.4 we recommended that sporadic ligatures should not be encoded by use of separate entities but by the element <seg> with the attribute @type="ligature". A sporadic ligature is basically a joining of two base line characters which together do not reflect a separate phonological value. This is the case with ligatures such as “s+k” and “p+p” which in this respect are identical to “s” + “k” and “p” + “p”.
However, some ligatures are formed in such a manner that it is difficult to distinguish the separate parts. That applies to the ligature of long s + h, k and þ. In these cases, we suggest that it is advisable to use individual entities. These characters must be referred to the Private Use Area.
Sometimes, a horizontal bar is used across these ligatures. The bar may be encoded separately with its usual entity, &bar; (cf. ch. 6.4.1 above) or with a character located in the Private Use Area.
6.5.7 The character “r” as interlinear ligature A quite special type of abbreviation is interlinear “r” in ligature with e.g. “þ”. We suggest encoding this as a sporadic ligature of “þ” and interlinear “r”.
6.5.8 Sharp “s”In late Old Norwegian, the “sharp s” appears in a number of abbreviations, e.g. for “skilling”, “smør” and “son”. The German character “sharp s” is defined in Unicode 5.0 as 00DF LATIN SMALL LETTER SHARP S in the range Latin-1 Supplement. We recommend uisng the ISO entity “ß” also when this character is used as an abbreviation mark. The element <am> will indicate clearly that it is an abbreviation mark, not an ordinary character. See the discussion on the full stop in ch. 6.3.8 above.
6.6 List of abbreviation marksAn extensive list of abbreviation characters is found in the MUFI character recommendation, cf. Appendix A below. |
First published 20 May 2003. Last updated 12 July 2016. Webmaster. |