
Chapter 2. Basic units: characters and words
Version 1.0 (20 May 2003)
2.1
Introduction
2.2
Characters
2.3
Words
2.1 Introduction
The basic unit in any transcription of an alphabetic script is the individual letters. In a linguistic context a distinction is often made between the abstract entity of a grapheme and the representation of graphs in a written document. Variant forms are referred to as allographs, e.g. the Roman type of s and the Fraktur (black letter) type. The terminology is analogous to the distinction between phonemes, phones and allophones. For a general introduction to this terminology, see Sture Allén 1971 or, more recently, Manfred Kohrt 1985.
In this handbook we shall adopt the terminology of the Unicode standard. The fundamental distinction drawn is between characters and glyphs. Characters are, as Unicode defines it, "the smallest components of written language that have semantic value", while glyphs are "the shapes that characters can have when they are rendered or displayed" (cf. Unicode 3.1, ch. 2.2). What the transcriber sees in the source document is a series of individual glyphs, and the act of transcribing essentially involves connecting these glyphs to the characters at the transcriber's disposal.
The concept of a character is similar to, but not identical with the linguistic concept of a grapheme. These concepts are notoriously difficult, but for the purposes of this handbook we believe that the Unicode usage is robust and sufficiently well-defined.
The Unicode standard puts great emphasis on the fact that individual characters may be represented by a number of glyphs, and is therefore reticent to accept as new characters what it percieves to be variant glyphs. It will be obvious to most people that the various shapes of letters in printed type faces, such as Baskerville, Palatino, Helvetica etc., should not be seen as different characters, as shown in fig. 2.1.
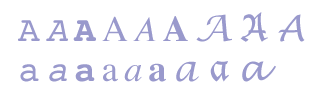
Fig. 2.1 Various shapes (glyphs) of the characters "A" and "a" in Courier, Times and Lucida typefaces
Unicode draws a distinction between small (minuscule) characters such as "a" and large (majuscule) characters such as "A", since there is a possible semantic value attached to each set of characters. Thus, "the white house" can refer to any house which is white in colour, while "the White House" refers (normally) to one specific building. It can be argued that the same applies to the distinction between Roman types, "a", and italics, "a". For example, while "Metope" refers a poem by the Norwegian author Olaf Bull, Metope (according to a widespread bibliographical practice) refers to the book in which this poem is published (a book which, co-incidentally, bears the same name as one of the poems contained in the book). However, Unicode does not regard italics (or bold type) as individual characters. There are good reasons for this, but the example serves to illustrate the fact that the definition of a character is not always clear-cut.
2.2 Characters
Medieval Nordic manuscripts were written in the Latin alphabet from the very beginning. The basic inventory is thus the characters a-z / A-Z. They were supplemented with a number of new (or borrowed) characters, several ligatures and a variety of diacritical marks. There was also a large number of abbreviation marks in use, especially in Old Icelandic and Old Norwegian manuscripts. We shall go through the inventory of ordinary characters, i.e. those based on the set a-z / A-Z, in ch. 5 and abbreviation marks in ch. 6, and we shall refer to both types as characters. In fact, some abbreviation marks behave as ordinary characters in the sense that they occupy a separate position on the base line. On the other hand, many components of ordinary characters are diacritical, i.e. placed above (or through or below) another character, and thus akin to typical abbreviation marks. This means that the rules for transcribing ordinary characters and abbreviation marks should be identical.
We believe that it is possible to identify a base line in all texts, as shown in fig. 2.2. We recommend that the transcriber identify each separate character on the base line and record this in the same sequence as in the manuscript. Thus, the characters in fig. 2.2 would be transcribed as "abpþ". Note the use of an entity, "þ", for the last character. Entities are explained in ch. 1 and discussed further in ch. 5.

Fig. 2.2 Position of characters on the base line
If there are marks of any sort placed above, through or below any base line character, we recommend that these marks (if they are to be interpreted as characters) are transcribed immediately after the base line character. In general, we refer to these marks as diacriticals. As mentioned above, abbreviation marks are also frequently written above (and in some cases through or below) a base-line character. Assuming that the sign above "h" is referred to with the entity "&er;", the transcription of the very first word in fig. 2.3 would be "h&er;".

Fig. 2.3 Diacritical marks and abbreviation marks
Diacritical marks are often seen as forming an integral part of a base line character and the whole encoded as a single entity. This applies to accent marks, such as the one above "e" in fig. 2.3. This character is usually encoded as a single entity, in Unicode referred to as LATIN SMALL LETTER E WITH ACUTE and the hexidecimal code value 00E9. As we shall see below, it is possible to decompose this letter in Unicode and refer to it as a combination of LATIN SMALL LETTER E and COMBINING ACUTE ACCENT. We would like to emphasize that both encodings are equivalent.
Abbreviation marks, on the other hand, are usually treated as separate characters and encoded as entities in their own right. From a purely graphical point of view, the distinction between the acute accent in "é" and abbreviation marks such as the "zigzag" mark and the bar, both exemplified in fig. 2.3, is far from obvious, but the semantics are different. The acute accent may in some manuscripts be used to signify length, but it is often used quite freely, sometimes only to distinguish one minim character from another. Abbreviation marks have a definite (if sometimes ambiguous) meaning, and can be expanded into one or more characters; the zigzag mark above "h" in fig. 2.3 signifies "er", and the bar above "n" signifies another "n".
2.2.1 Rules for encoding characters
We suggest the following basic rules for encoding characters, irrespective of whether they are ordinary (alphabetic) characters or abbreviation marks.
1. Each character is encoded according to its position in the direction of writing.
2. Alphabetical characters on the base line are encoded first. If the character belongs to the ordinary Latin character set a-z / A-Z (commonly known as ISO 646 or ASCII) it is encoded as such. If not, it is encoded as an entity, as explained in ch. 5 below.
3. Abbreviation marks occupying a separate position on the base line are encoded in the same manner as alphabetical characters. This applies to e.g. the Tironian nota for "et" (in Latin) or "ok" (in Old Norse), which is encoded with the entity "&et;" as explained in ch. 6.2.
4. Alphabetical characters with diacritical marks, e.g. "é", are encoded in one of two equivalent ways:
4.1 As a base line character + one
or more combining marks. Thus the character "é" would be
encoded as "e" + "&combacute;" (the latter entity meaning
COMBINING ACUTE ACCENT).
4.2 As a composite base line character and encoded with a single
entity. Thus the character "é" would be encoded as
"é".
5. Characters with abbreviation marks are encoded in the same manner as alphabetical characters, i.e. in one of two equivalent ways:
5.1 As a base line character + one
or more combining marks. Thus the first character in fig. 3.2 above
would be encoded as "h" + "&er;" (the latter entity meaning
COMBINING ABBREVIATION MARK "ER").
5.2 As a composite base line character and encoded with a single
entity. Thus the above character might be encoded with a single
entity, e.g. as "&her;".
As a rule, we would recommend the first solution, since the number of combinations of base line characters and combining abbreviation marks is very high. Cf. the discussion in ch. 6.3.
6. If there are more than one combining character, they are encoded in this order:
(a) Combinations with the base line
character within the x height of the base line character.
(b) Combinations with the base line character outside its x height,
but still in contact with it.
(c) Combinations with the base line character outside its x height,
and without any contact with it.
7. If there are more than one combining character in any of the three positions defined in (6) above, they are encoded in a clockwise direction, beginning at 6 o'clock and moving through 9 o'clock, 12 o'clock etc.
2.2.2 Entities and Unicode values
By using entities it is possible to define as many characters as one believes are necessary for the transcription of a certain corpus of texts. Entities are used in numerous encoding schemes, and for the sake of transparency and interchangeability, we recommend that entities as far as possible conform to the standard ISO entity sets. An updated list of ISO conformant entities can be found at the Oasis web site:
In addition to the ISO entities, we need a number of entities for characters not designated in this standard. The rules for constructing new entites are discussed in ch. 5 and 6 below.
Furthermore, entities need to be displayed by appropriate fonts. Therefore, we strongly recommend that all entities are defined and described with reference to the Unicode standard. In this standard, each character is identified by a unique code point, exemplified by a typical graphic form ("glyph"), and given a descriptive name. An increasing number of fonts contains a large set of characters in the Unicode standard. This greatly facilitates the display of encoded texts.
The Basic Multilingual Plane of Unicode has 65,536 different code points. This includes a large Private Use Area (PUA), comprising some 6,000 code points. This area can be used for characters not defined in the standard (so far). Our present recommendation is to use this area for characters not included in the Unicode standard. It should be noted that the use of PUA is an interim solution. A long-term solution is obviously to apply to Unicode for the inclusion of additional characters and/or use other rendering techniques (such as OpenType).
Code points in Unicode are usually given in hexadecimal format, in which each digit spans a sequence of 16 positions, 0-1-2-3-4-5-6-7-8-9-A-B-C-D-E-F. Thus, 0001 equals 1 in the decimal system, 000F equals 16, 0010 equals 17 etc. The whole range thus goes from 0000 to FFFF (65,536). The PUA is located at E000-F8FF.
The Latin alphabet is the first to be described in the Unicode standard. As was mentioned, many characters in Unicode can be defined in several ways, either as a single, composite character or as combination of a base line character and one or more combining marks.
(a) Commonly used characters have a single description in Unicode. This applies to all base line characters in the Latin alphabet.
Glyph Character /
entity Code point Unicode descriptive
name a 0061 LATIN SMALL LETTER
A
![]()
(b) Composite characters may be described in more than one way. Thus "a with acute accent" can be encoded as a combination of "a" and a combining acute accent or as a single character, "a with acute accent". Both descriptions are equivalent:
Glyph Character /
entity Code point Unicode descriptive
name a +
&combacute; 0061 + 0301 LATIN SMALL LETTER A +
COMBINING ACUTE ACCENT á 00E1 LATIN SMALL LETTER A WITH
ACUTE
![]()
![]()
Note that the entity á belongs to the ISO set, while &combacute; is an example of an entity defined in this handbook (cf. ch. 5 below for more information).
(c) Some characters are not found in Unicode, and must therefore be allocated to the Private Use Area (PUA), either as a character with its own code point or as a combination of an existing character and a combining diacritical mark in the PUA. The ligature "av" is not included in Unicode, and since we (at the moment) would rather not encode it as a sequence of "a" + "zero width joiner" + "v", we have allocated it to a code point in the PUA, E406.
Glyph Character /
entity Code point Unicode descriptive
name &avlig; E406 LATIN SMALL LIGATURE
AV
![]()
This may look unnecessary complicated. It should be borne in mind, however, that the great majority of characters are defined in Unicode, and in many transcriptions the need for special characters in the PUA will not arise. With appropriate fonts, the transcriber does not need to spend much time on the technicalities of this problem.
For a complete list of entities and Uncode code points, including PUA, cf. the character list.
2.2.3 Rules for naming of characters
For practical reasons, all characters needed for the transcription of Medieval Nordic manuscripts should be given descriptive names. We have found the naming scheme in Unicode 3.2 to be a good model. There are, however, a considerable number of characters which so far have not been defined and described in Unicode. For these characters we must resort to the Private Use Area, and we need rules for the naming of such characters.
Descriptive names have basically the same syntax as in rules (6) and (7) in ch. 2.2.1 above. The following examples refer to characters in the official Unicode standard and thus serve to illustrate the naming scheme.
1. Base line character. Glyph Descriptive
name LATIN SMALL LETTER
A
![]()
2. Modification of a base line
character within its x-height. Glyph Descriptive
name LATIN SMALL LETTER O WITH
STROKE
![]()
3. Modification of a base line
character touching the base character outside its x-height. As
explained in ch. 2.2.2 above, this character can be encoded and
described in two equivalent ways. Glyph Descriptive
name LATIN SMALL LETTER O +
COMBINING OGONEK
![]()
= LATIN SMALL LETTER O WITH OGONEK
4. Modification of a base line
character not touching the base line character itself. Also this
character can be encoded and described in two equivalent ways. Glyph Descriptive
name LATIN SMALL LETTER O WITH
STROKE + COMBINING ACUTE ACCENT
![]()
= LATIN SMALL LETTER O WITH STROKE AND ACUTE
5. More than one modification.
Here, there are in fact three equivalent ways of encoding and
describing this character. Glyph Descriptive
name LATIN SMALL LETTER O +
COMBINING OGONEK + COMBINING ACUTE ACCENT
![]()
= LATIN SMALL LETTER O WITH OGONEK + COMBINING ACUTE
ACCENT
= LATIN SMALL LETTER O WITH OGONEK AND ACUTE
For a full discussion of characters and entity names, please refer to ch. 5 below.
2.3 Words
As a rule, Medieval Nordic manuscripts in the Latin alphabet are written with a clearly identifiable space between each word. This obviously facilitates the work for the transcriber, since the word is a basic linguistic unit in grammars and dictionaries. It is, however, useful to draw a distinction between graphical words and lexical words. A graphical word is a sequence set out by space on either side, while a lexical word is a member of the set of word forms defined by grammars and dictionaries for the language in question. In the great majority of cases, graphical and lexical words are identical. However, in Medieval Nordic manuscripts, we sometimes see that a preposition and its object may be written as a single word, or that what we would now regard as compounds are written as two separate words.

Fig. 2.4 Text adopted from Barlaams saga ok Josaphats, Holm perg. fol. nr 6, f. 138
In a transcription, word division can simply be entered by the space bar on the keyboard. Thus, the text in fig. 2.4 could be transcribed as
veiði kona mykyl hevir hon veret ok miok agiarn&bar; aveiðiskap
Since the word is a basic linguistic unit and also the locus of many types of mark-up we recommend that each word is set out by the <w> element ("w" means "word"). This convention also makes it possible to make a distinction between graphical and lexical words. The transcription would now look like this:
<w>veiði kona</w> <w>mykyl</w> <w>hevir</w> <w>hon</w> <w>veret</w> <w>ok</w> <w>miok</w> <w>agiarn&bar;</w> <w>a</w><w>veiðiskap</w>
Note that the sequence "veiði kona" appears within a single element. This means that the transcriber interprets it as one lexical word, "veiðikona". The space is left untouched, so that in a display of the transcription, the sequence will still show up as two graphical words, "veiði" and "kona". However, since both graphical words are placed within a single element any attributes to the word, e.g. the lemma, will refer to both parts.
Conversly, the sequence "aveiðiskap" appears within two elements, one identifying "a" and another "veiðiskap". Since no space has been added, the two lexical words will appear as one graphical word when the transcription is displayed. Any attributes, however, will be attached to each of the lexical words which make up the graphical word; in this case the preposition "a" and the noun "veiðiskap".
From a lexicographical point of view, lemmatisation of the text is very valuable. This is conviently done by attaching an attribute to each word in the text, identified with the <w> element, as exemplified here:
<w
lemma="veiðikona">veiði
kona</w>
<w
lemma="mikill">mykyl</w>
<w
lemma="hafa">hevir</w>
<w
lemma="hon">hon</w>
<w
lemma="vera">veret</w>
<w
lemma="ok">ok</w>
<w
lemma="mj&ohbr;k">miok</w>
<w
lemma="ágjarn">agiarn&bar;</w>
<w
lemma="á">a</w>
<w
lemma="veiðiskapr">veiðiskap</w>
Lemmatisation is further discussed in ch. 8 below, and is here only given as an example of a word-based type of mark-up. Grammatical information can also be conveniently attached to the word through the pos (part of speech) attribute. This is also discussed in ch. 8.
|
Preliminary version created 17 January 2002. Version 1.0 published 20 May 2003. |